18. 清单
一个清单是可启动作业的主机集合,与 Ansible 清单文件相同。清单分为组,这些组包含实际的主机。组可以手动源自,通过在 AWX 中输入主机名,或来自其支持的云提供商之一。
注意
如果您有自定义动态清单脚本或 AWX 中尚未原生支持的云提供商,您也可以将其导入 AWX。请参阅AWX 管理指南中的清单文件导入。
“清单”窗口显示当前可用的清单列表。清单列表可以按名称排序并按类型、组织、描述、清单的所有者和修改者或根据需要搜索其他条件进行搜索。
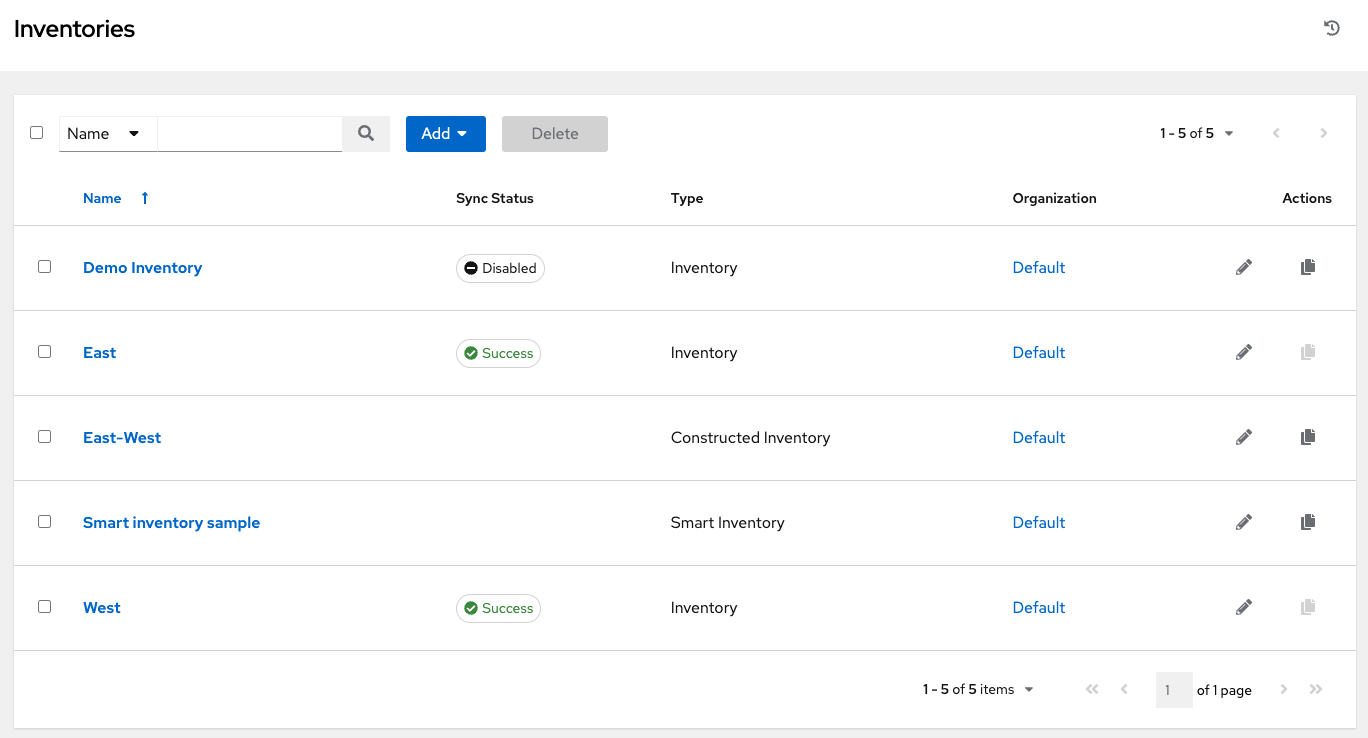
清单详细信息列表包括
**名称**:清单名称。单击清单名称将导航到所选清单的属性屏幕,该屏幕显示清单的组和主机。(此视图也可以从
 图标访问。)
图标访问。)
状态
状态包括:
**成功**:当清单源同步成功完成时
**已禁用**:未向清单添加清单源
**错误**:当清单源同步完成时出现错误
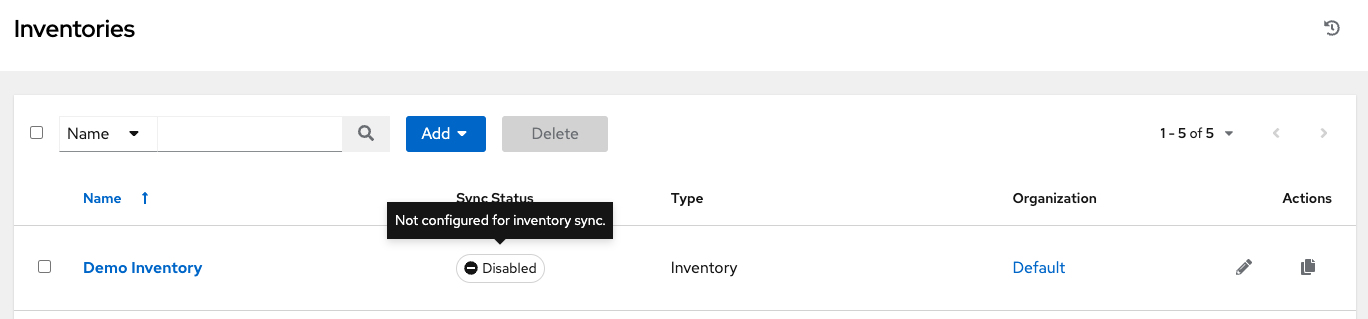
各种状态的清单示例,包括一个包含禁用状态详细信息的清单
**类型**:标识它是标准清单、智能清单还是构造清单。
**组织**:清单所属的组织。
**操作**:以下操作可用于所选清单
**编辑** (
):编辑所选清单的属性**复制** (
 ):复制现有清单作为创建新清单的模板
):复制现有清单作为创建新清单的模板
18.1. 智能清单
智能清单是由存储的搜索定义的主机集合,可以像标准清单一样查看并易于用于作业运行。组织管理员对他们组织中的清单具有管理员权限,并且可以创建智能清单。智能清单由KIND=smart标识。您可以使用与搜索相同的方法定义智能清单。InventorySource直接与清单关联。
注意
智能清单已弃用,将在将来的版本中删除。鼓励用户考虑迁移到构造清单以进行增强和替换。
Inventory模型具有以下默认情况下为空但针对智能清单相应设置的新字段
kind对于智能清单设置为smarthost_filter已设置,并且kind对于智能清单已设置为smart。
host模型具有一个相关的端点smart_inventories,它标识主机关联的所有智能清单的集合。每次针对智能清单运行作业时都会更新成员关系表。
注意
要更频繁地更新成员关系,您可以将基于文件的设置AWX_REBUILD_SMART_MEMBERSHIP更改为**True**(默认值为 False)。这将在以下事件中更新成员关系
添加新主机
修改现有主机(更新或删除)
添加新的智能清单
修改现有智能清单(更新或删除)
您可以查看实际的清单,但不能编辑
作为清单源同步结果创建的主机和组的名称
组记录不可编辑或移动
您不能从智能清单主机端点(/inventories/N/hosts/)创建主机,就像普通清单一样。智能清单的管理员有权编辑名称、描述、变量等字段,以及删除的能力,但无权修改host_filter,因为这会影响哪些主机(在另一个清单中具有主要成员关系)包含在智能清单中。请注意,host_filter仅适用于智能清单组织内的清单中的主机。
要修改host_filter,您需要是清单组织的组织管理员。组织管理员已经对组织内的所有清单具有隐式的“管理员”访问权限,因此,这不会授予他们之前没有的任何权限。
智能清单的管理员可以向其他用户(也并非您的组织的管理员)授予“使用”、“adhoc”等权限,这些权限将允许角色指示的操作,就像其他标准清单一样。但是,这不会赋予他们对主机的任何特殊权限(存在于不同的清单中)。它不会允许他们直接读取主机的权限,也不会允许他们在/#/hosts/下查看其他主机,尽管他们仍然可以在智能清单主机列表下查看主机。
在某些情况下,您可以修改以下内容
在具有清单源的清单上手动创建的新主机
在作为清单源同步结果创建的组中
与智能清单关联的主机在查看时体现出来。如果智能清单的结果包含多个具有相同主机名的主机,则智能清单中只会包含其中一个匹配的主机,按主机 ID 排序。
主机和组上的变量即使作为本地系统管理员用户也无法更改。
18.1.1. 智能主机过滤器
您可以使用搜索过滤器为清单填充主机。此功能利用了事实搜索功能的功能。
在作业模板运行期间,Ansible playbook 生成的 Fact 会在每次为作业模板设置use_fact_cache=True时存储到 AWX| 的数据库中。新的 Fact 会与现有的 Fact 合并,并且是针对每个主机的。这些存储的 Fact 可用于通过/api/v2/hosts端点使用GET查询参数host_filter过滤主机,例如:/api/v2/hosts?host_filter=ansible_facts__ansible_processor_vcpus=8
host_filter参数允许
通过 () 分组
使用布尔 AND 运算符
__引用关系字段中的相关字段__用于 ansible_facts 以分隔 JSON 密钥路径中的键[]用于表示路径规范中的 JSON 数组""可用于值中,当值中需要空格时
“经典” Django 查询可以嵌入到
host_filter中
示例
/api/v2/hosts/?host_filter=name=localhost
/api/v2/hosts/?host_filter=ansible_facts__ansible_date_time__weekday_number="3"
/api/v2/hosts/?host_filter=ansible_facts__ansible_processor[]="GenuineIntel"
/api/v2/hosts/?host_filter=ansible_facts__ansible_lo__ipv6[]__scope="host"
/api/v2/hosts/?host_filter=ansible_facts__ansible_processor_vcpus=8
/api/v2/hosts/?host_filter=ansible_facts__ansible_env__PYTHONUNBUFFERED="true"
/api/v2/hosts/?host_filter=(name=localhost or name=database) and (groups__name=east or groups__name="west coast") and ansible_facts__an
您可以通过主机名、组名和 Ansible facts 搜索 host_filter。
组搜索的格式为
groups.name:groupA
事实搜索的格式为
ansible_facts.ansible_fips:false
您还可以执行智能搜索,它包含主机名和主机描述。
host_filter=name=my_host
如果 host_filter 中的搜索词是字符串类型,要使其值成为数字(例如 2.66),或 JSON 关键字(例如 null、true 或 false)有效,请在值周围添加双引号,以防止 AWX 错误地将其解析为非字符串
host_filter=ansible_facts__packages__dnsmasq[]__version="2.66"
18.1.2. 使用 ansible_facts 定义主机过滤器
要在创建智能清单时使用 ansible_facts 定义主机过滤器,请执行以下步骤
在“创建新的智能清单”屏幕中,单击**智能主机过滤器**字段旁边的
 按钮,以打开一个弹出窗口,用于筛选此清单的主机。
按钮,以打开一个弹出窗口,用于筛选此清单的主机。
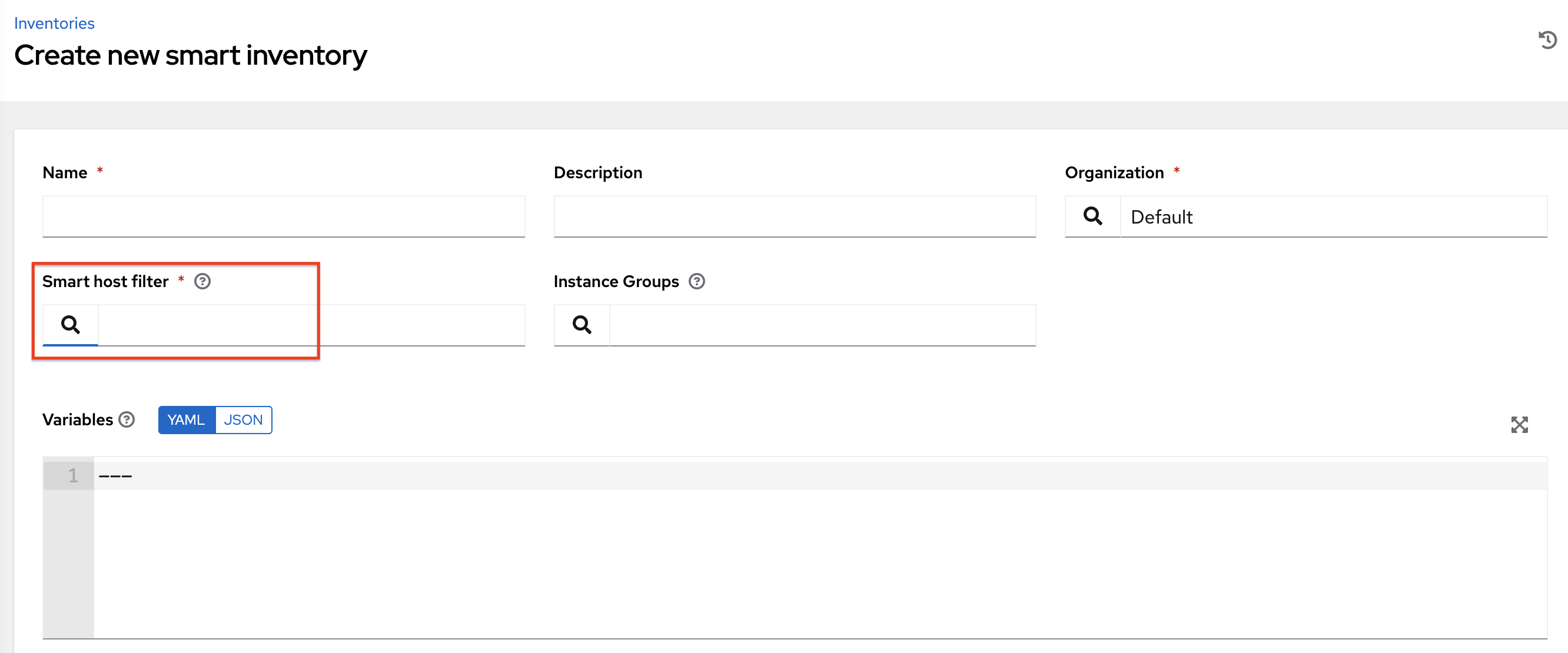
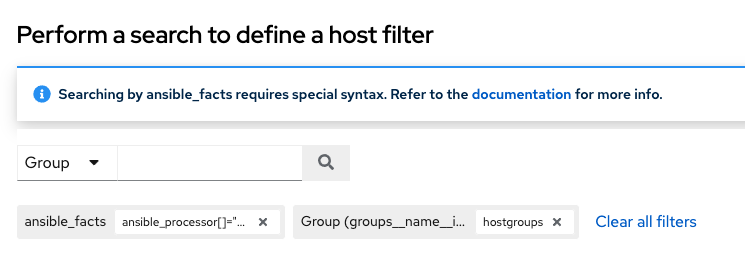
在搜索弹出窗口中,将搜索条件从**名称**更改为**高级**,然后从**键**字段中选择**ansible_facts**。
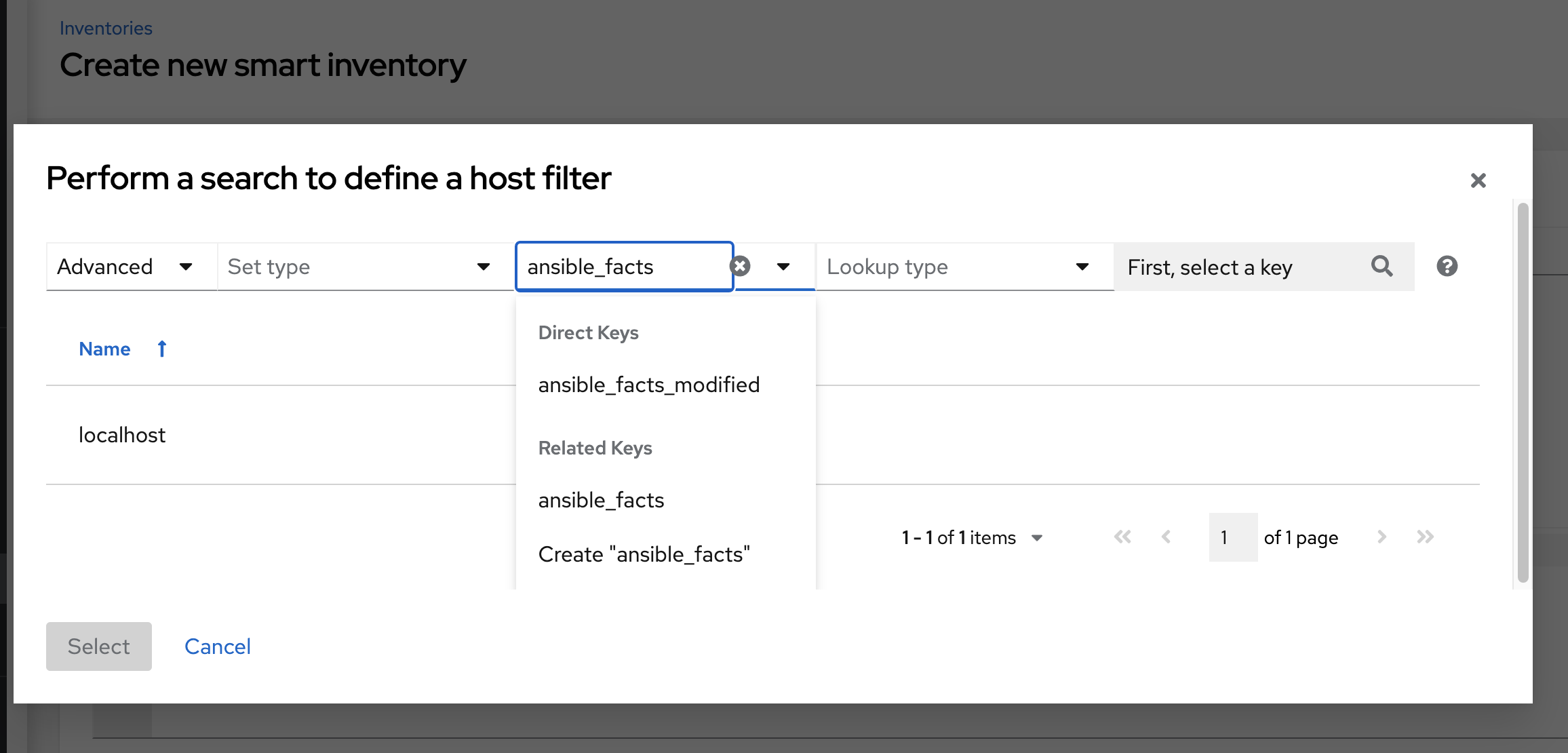
如果您想添加以下 ansible 事实:
/api/v2/hosts/?host_filter=ansible_facts__ansible_processor[]="GenuineIntel"
在搜索字段中,输入 ansible_processor[]="GenuineIntel"(没有额外的空格或 __ 在值之前),然后按**[Enter]**。
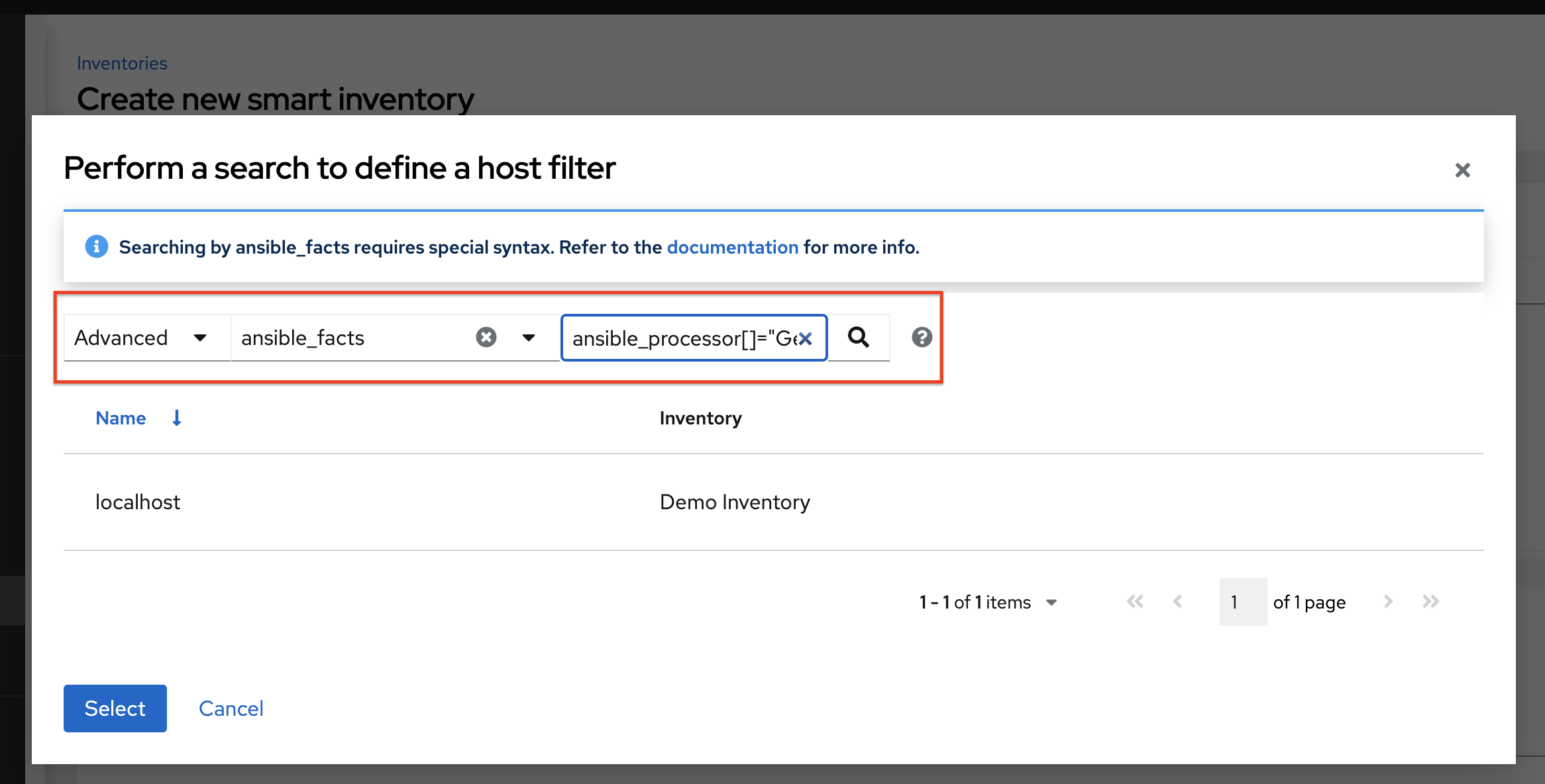
指定 ansible 事实的搜索条件结果将填充到窗口的下部。
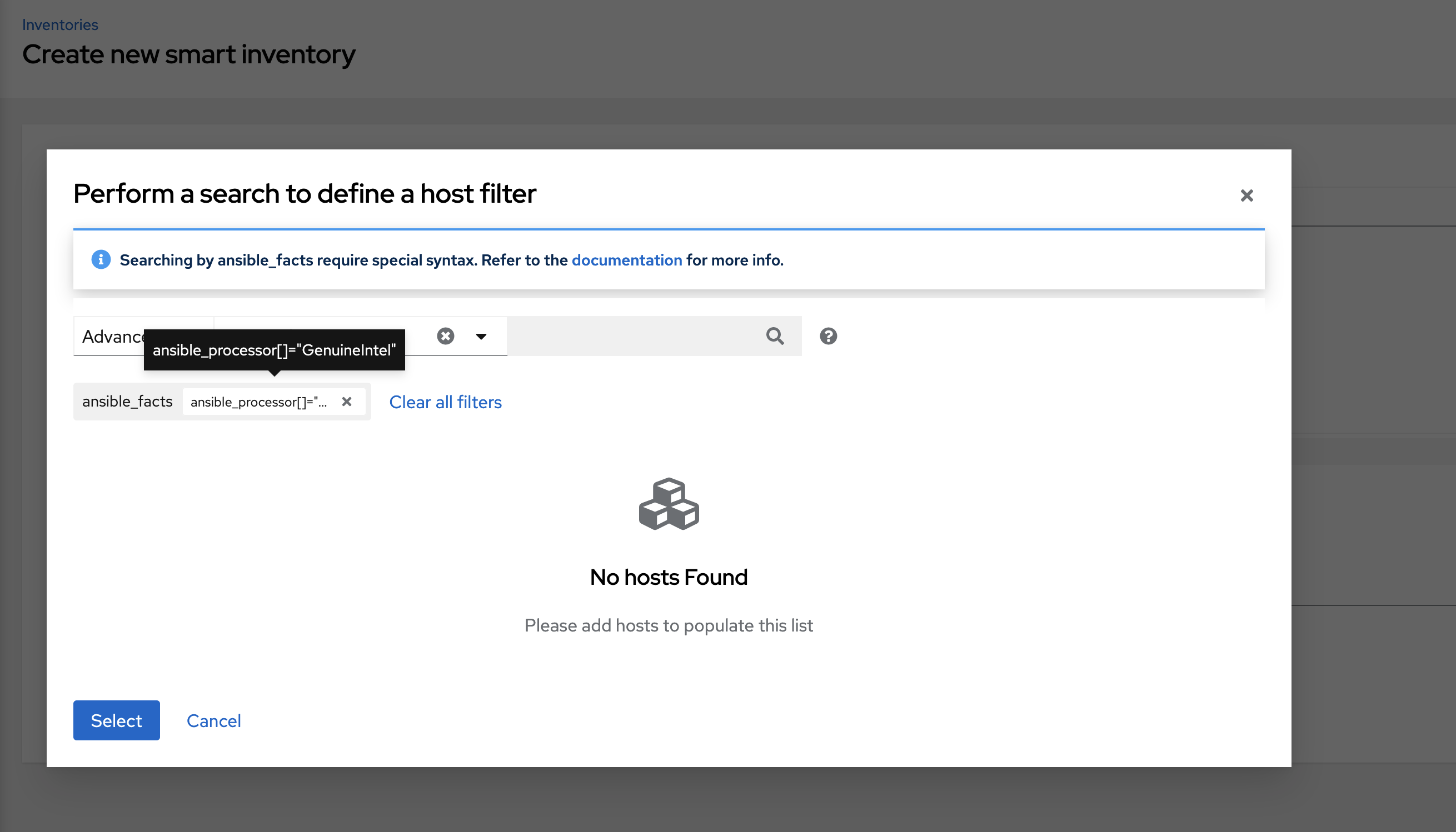
单击**选择**将其添加到**智能主机过滤器**字段。
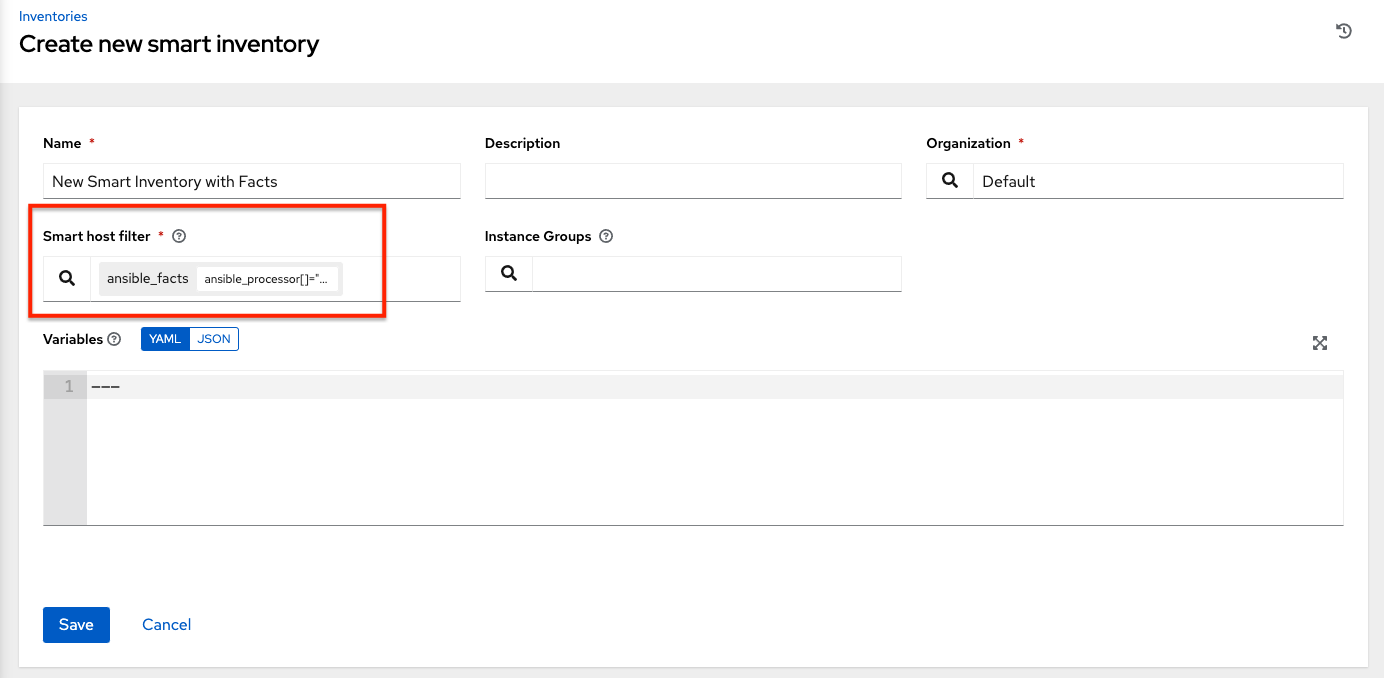
单击**保存**以保存新的智能清单。
新的智能清单的“详细信息”选项卡打开,并在**智能主机过滤器**字段中显示指定的 ansible 事实。
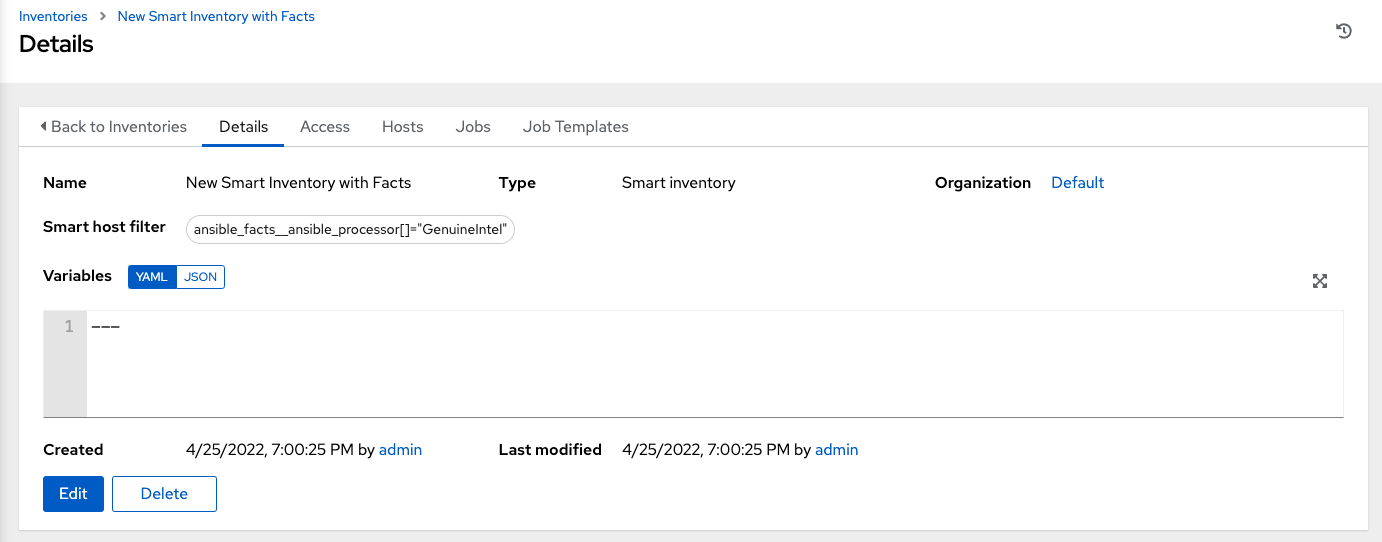
在“详细信息”视图中,您可以通过单击**编辑**来编辑**智能主机过滤器**字段,并删除现有过滤器、清除所有现有过滤器或添加新的过滤器。
18.2. 组合清单
作为平台用户,此功能允许从输入清单列表创建新的清单(称为组合清单)。组合清单包含其输入清单中主机和组的副本,允许作业定位跨多个清单的服务器组。可以将组和 hostvars 添加到清单内容中,并且可以筛选主机以限制组合清单的大小。组合清单解决了智能清单主机筛选模型的一些限制,并利用了 Ansible 核心组合清单模型。
区分组合清单和智能清单的关键因素是
可用的普通 Ansible hostvars 命名空间
它们提供组
智能清单将 host_filter 作为输入,并创建一个结果清单,其中包含其组织中清单中的主机。组合清单将 source_vars 和 limit 作为输入,并将 input_inventories 转换为新的清单,包括组。然后,可以在 limit 字段中引用组(现有或构造的组),以减少生成的主机数量。
例如,您可以根据以下主机属性构建组
RHEL 主/次版本
Windows 主机
在特定区域标记的基于云的实例
其他
后续部分中描述的这些示例按输入清单的结构进行组织。
18.2.1. 组名称和变量筛选
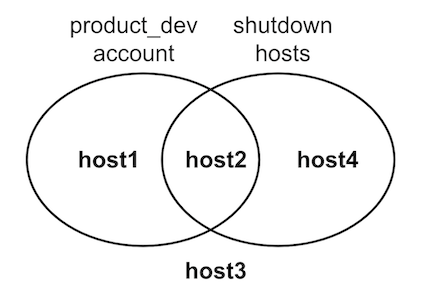
这里演示了两种不同的条件来描述输入清单内容
第一个条件是在主机上定义的
state变量设置为shutdown第二个条件是属于具有
account_alias变量设置为product_dev的组。
变量 account_alias 用于演示组变量。在这个假设中,每个帐户都有自己的组,组变量提供有关这些帐户的元数据,这在云源清单中很常见。这些变量显示在 Ansible 中的一般 hostvars 命名空间中,这就是为什么它在 source_vars 中没有特殊处理的原因。
输入清单中的主机将符合一个条件、另一个条件、都不符合或都符合。为了演示目的,这将导致总共四个主机。
此文件夹将清单定义为名为 two_conditions.ini 的 ini 类型。
[account_1234]
host1
host2 state=shutdown
[account_4321]
host3
host4 state=shutdown
[account_1234:vars]
account_alias=product_dev
[account_4321:vars]
account_alias=sustaining
这里的目标是仅返回存在于 account_alias 变量为 product_dev 的组中的关闭主机。对此有两种方法,都以 yaml 格式显示。建议使用第一种方法。
构建 2 个组,限制为交集
source_vars:
plugin: constructed
strict: true
groups:
is_shutdown: state | default("running") == "shutdown"
product_dev: account_alias == "product_dev"
limit: is_shutdown:&product_dev
此组合清单输入为这两类都创建了一个组,并使用 limit(主机模式)仅返回这两个组交集中的主机,这在 Ansible 中的主机模式 中有记录。
此外,当变量可能已定义也可能未定义(取决于主机)时,您可以提供一个默认值,例如 | default("running"),如果您知道未定义时它应该是什么值。这有助于调试,如 调试技巧 部分所述。
构建 1 个组,限制为组
source_vars:
plugin: constructed
strict: true
groups:
shutdown_in_product_dev: state | default("running") == "shutdown" and account_alias == "product_dev"
limit: shutdown_in_product_dev
此输入创建一个仅包含匹配这两个条件的主机的组。然后,限制仅为组名本身,返回仅 **host2**,与之前的方法相同。
18.2.1.1. 调试技巧
将 strict 参数设置为 True 非常重要,以便您可以调试模板问题。如果模板渲染失败,您将在该组合清单的关联清单更新中收到错误。
遇到错误时,提高详细程度以获取更多详细信息。
提供一个默认值,例如 | default("running") 是 Ansible 中 Jinja2 模板的通用用法。这样做可以避免在设置 strict: true 时特定模板出现错误。您还可以设置 strict: false,并允许模板产生错误,这将导致主机未包含在该组中。但是,这样做会使将来难以调试问题,如果您的模板继续变得越来越复杂。
但是,如果模板没有生成预期的清单内容,您可能仍然需要调试模板的预期功能。例如,如果 groups 组具有复杂的过滤器(如 shutdown_in_product_dev),但在结果组合清单中不包含任何主机,则使用 compose 参数进行调试。像这样
source_vars:
plugin: constructed
strict: true
groups:
shutdown_in_product_dev: state | default("running") == "shutdown" and account_alias == "product_dev"
compose:
resolved_state: state | default("running")
is_in_product_dev: account_alias == "product_dev"
limit: ``
使用空白 limit 运行将返回所有主机。您可以使用它来检查特定主机上的特定变量,从而深入了解 groups 中的问题所在。
18.2.2. 嵌套组
这里使用两个组的清单内容(其中一个组是另一个组的子组)来演示嵌套组。子组在其内部有一个主机,父组定义了一个变量。由于 Ansible 核心的工作方式,父组的变量将在运行剧本时在命名空间中可用,并且可以用于筛选。
以名为 nested.yml 的 yaml 格式定义清单文件
all:
children:
groupA:
vars:
filter_var: filter_val
children:
groupB:
hosts:
host1: {}
ungrouped:
hosts:
host2: {}
这里的目标是根据间接组成员身份筛选主机(因为 host1 位于 groupB 中,它也位于 groupA 中)。
18.2.2.1. 根据嵌套组名称筛选
使用以下 yaml 格式根据嵌套组名称进行筛选
source_vars:
plugin: constructed
limit: groupA
18.2.2.2. 根据嵌套组属性筛选
这展示了如何根据组变量进行筛选,即使主机是该组的间接成员。
在清单内容中,您可以看到host2预期不会定义变量filter_var,因为它不属于任何组。由于使用了strict: true,因此会使用默认值,以便那些未定义该变量的主机。这样,host2将从表达式中返回False,而不是产生错误。host1将从其组继承该变量,并会被返回。
source_vars:
plugin: constructed
strict: true
groups:
filter_var_is_filter_val: filter_var | default("") == "filter_val"
limit: filter_var_is_filter_val
18.2.3. Ansible 事实
要使用 Ansible 事实创建清单,您需要对具有gather_facts: true的清单运行剧本。实际的事实因系统而异。以下示例问题举例说明了一些示例案例,并不旨在解决所有已知场景。
18.2.3.1. 根据环境变量过滤
此处演示了一个示例问题,该问题涉及使用 yaml 格式根据环境变量进行过滤。
source_vars:
plugin: constructed
strict: true
groups:
hosts_using_xterm: ansible_env.TERM == "xterm"
limit: hosts_using_xterm
18.2.3.2. 按处理器类型过滤主机
此处演示了一个示例问题,该问题涉及使用 yaml 格式根据处理器类型(Intel)过滤主机。
source_vars:
plugin: constructed
strict: true
groups:
intel_hosts: "GenuineIntel" in ansible_processor
limit: intel_hosts
注意
与智能清单一样,构建的清单中的主机不会计入您的许可证配额,因为它们引用了原始清单主机。此外,原始清单中禁用的主机将不会包含在构建的清单中。
通过ansible-inventory运行的清单更新会创建构建的清单内容。这始终配置为在作业之前启动时更新,但如果更新时间过长,您仍然可以选择缓存超时值。
创建构建的清单时,API 会强制它始终与一个清单源关联。所有清单更新都与一个清单源关联,并且构建的清单所需字段(source_vars和limit)是清单源模型中已存在的字段。
18.2.4. 用户界面
按照后续部分添加新的清单中描述的过程创建新的构建的清单。
构建的清单详细信息视图示例
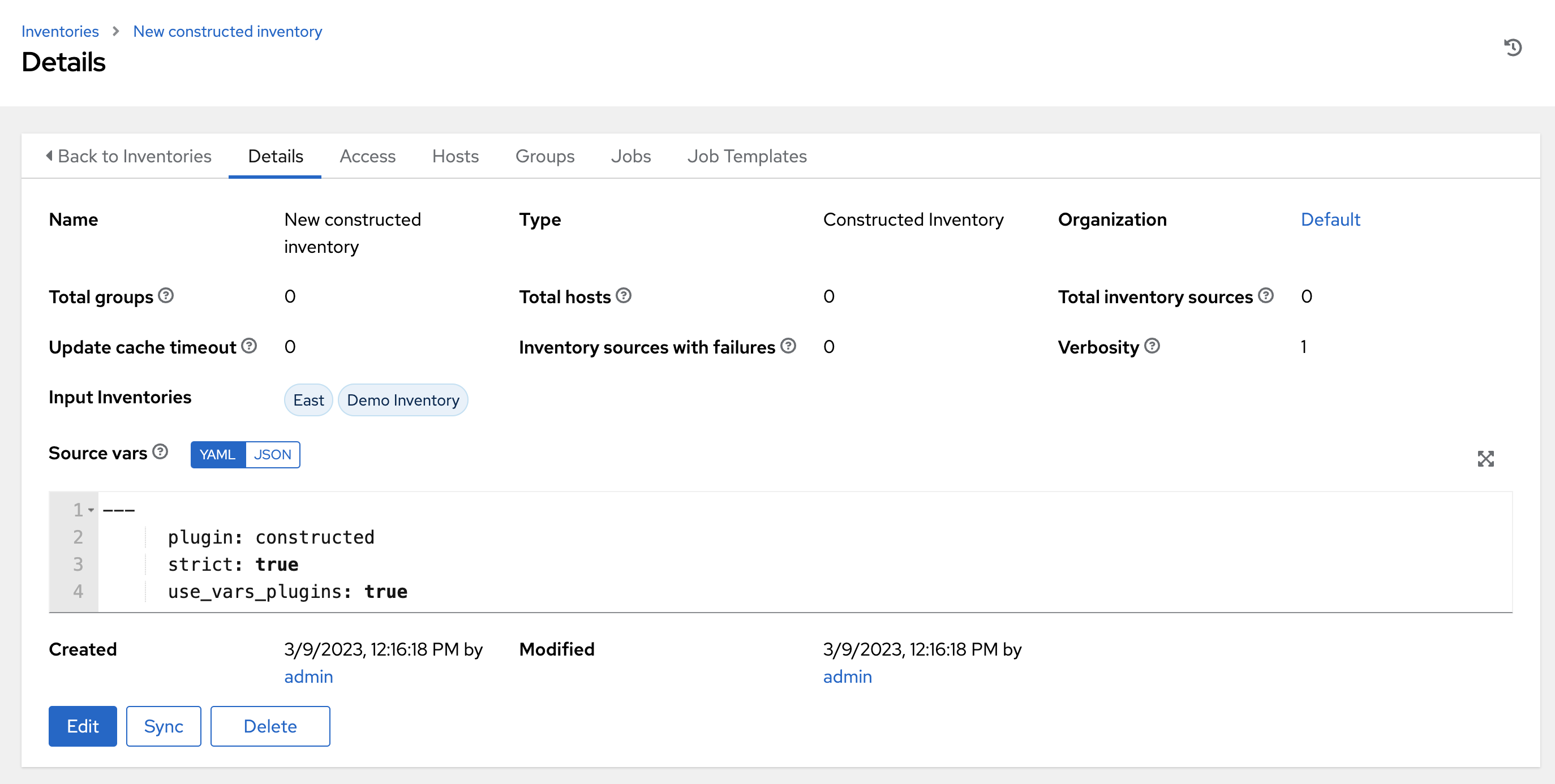
18.3. 清单插件
清单更新使用动态生成的 YAML 文件,这些文件由其各自的清单插件解析。用户可以通过清单源source_vars将新样式的清单插件配置直接提供给 AWX,适用于以下所有清单源
新创建的清单源配置将包含默认的插件配置值。如果您希望新创建的清单源与旧版源的输出匹配,则必须为该源应用一组特定的配置值。为了确保向后兼容性,AWX 使用每个源的“模板”将清单插件的输出强制为旧版格式。请参阅本指南的支持的清单插件模板部分,了解每个源及其各自的模板,以帮助您迁移到新样式的清单插件输出。
包含plugin: foo.bar.baz作为顶级键的source_vars将在运行时根据InventorySource源替换为相应的完全限定清单插件名称。例如,如果为InventorySource选择 ec2,则在运行时,插件将设置为amazon.aws.aws_ec2。
18.4. 添加新的清单
添加新的清单涉及多个组件
要创建新的标准清单、智能清单或构建的清单
点击添加按钮,然后选择要创建的清单类型。
清单类型在创建表单的顶部标识。
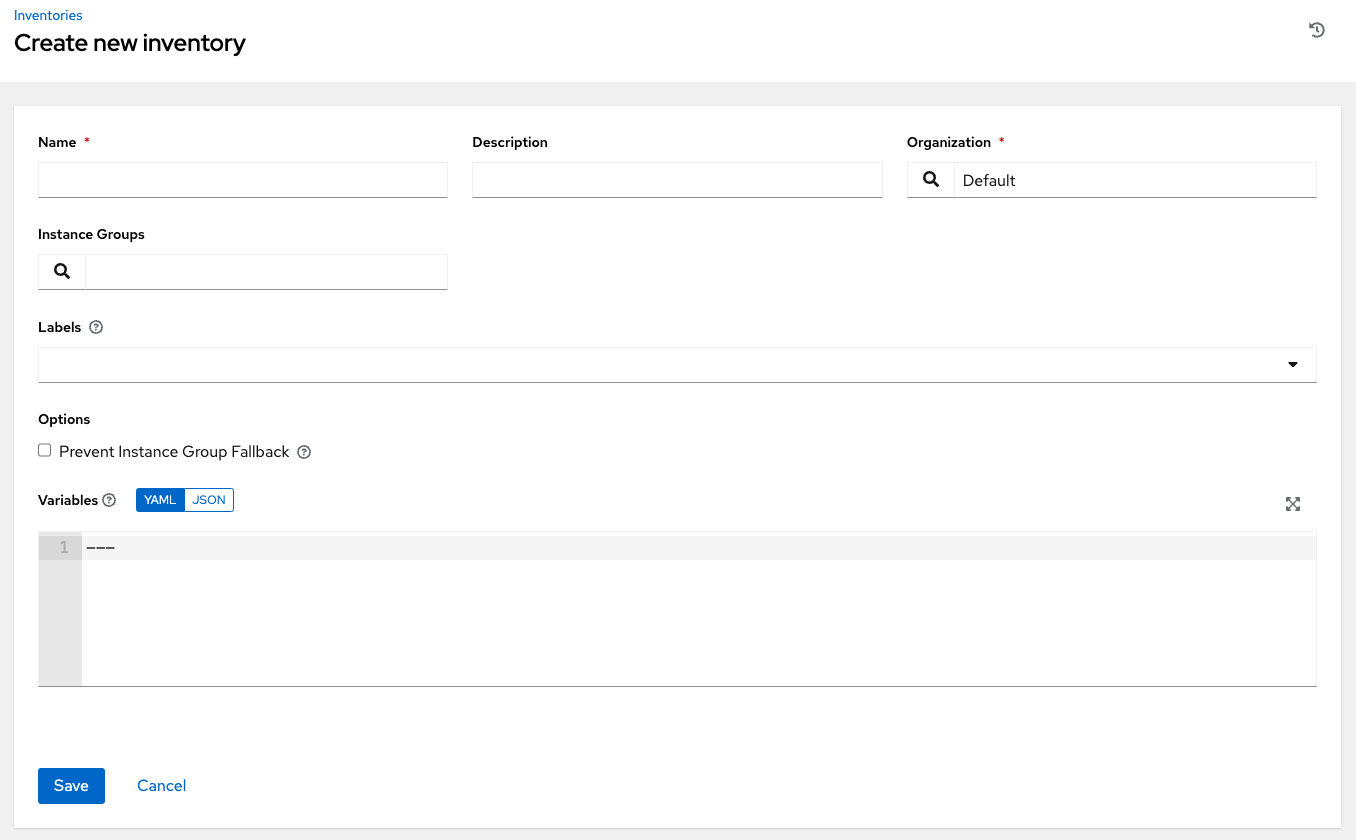
在以下字段中输入相应的详细信息
名称:输入适合此清单的名称。
描述:根据需要输入任意描述(可选)。
组织:必填。在可用的组织中进行选择。
智能主机过滤器: (仅适用于智能清单)点击
按钮打开一个单独的窗口,以过滤此清单的主机。这些选项基于您选择的组织。过滤器类似于标签,标签用于过滤包含这些名称的某些主机。因此,要填充智能主机过滤器字段,您需要指定一个包含所需主机的标签,而不是实际选择主机本身。在搜索字段中输入标签并按[Enter]。过滤器区分大小写。有关更多信息,请参阅智能主机过滤器部分。
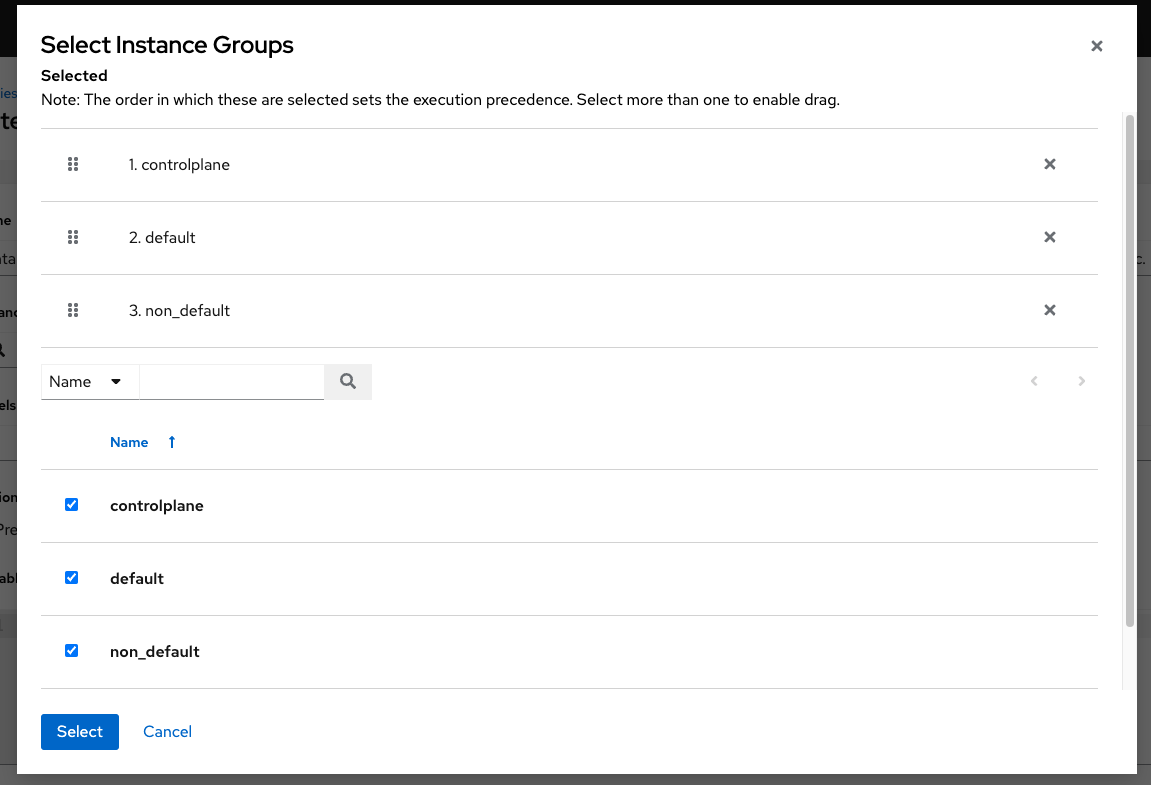
实例组:点击
按钮打开一个单独的窗口。选择此清单要运行的实例组。如果列表很长,请使用搜索缩小选项范围。您可以选择多个实例组并按所需的顺序对其进行排序。
标签:可选地提供描述此清单的标签,以便可以使用它们对清单和作业进行分组和过滤。
输入清单: (仅适用于构建的清单)指定要包含在此构建的清单中的源清单。点击
按钮从可用清单中进行选择。输入清单中的空组将复制到构建的清单中。缓存超时(秒): (仅适用于构建的清单)可选地设置希望缓存插件数据超时的时长。
详细程度: (仅适用于构建的清单)控制 Ansible 在执行与构建的清单关联的清单源相关的剧本时产生的输出级别。从普通到各种详细或调试设置中选择详细程度。这仅显示在“详细信息”报告视图中。详细日志记录包括所有命令的输出。调试日志记录非常详细,包括有关 SSH 操作的信息,这在某些支持实例中可能很有用。大多数用户不需要查看调试模式输出。
限制: (仅适用于构建的清单)限制与构建的清单关联的清单源返回的主机数量。您可以将组名称粘贴到限制字段中,以仅包含该组中的主机。有关更多详细信息,请参阅源变量。
选项:选中阻止实例组回退选项(仅适用于标准清单),以仅允许上面实例组字段中列出的实例组执行作业。如果未选中,则将根据控制作业运行位置中描述的层次结构使用执行池中的所有可用实例。点击
 图标以获取其他信息。
图标以获取其他信息。
注意
通过 API 为智能清单设置prevent_instance_group_fallback选项。
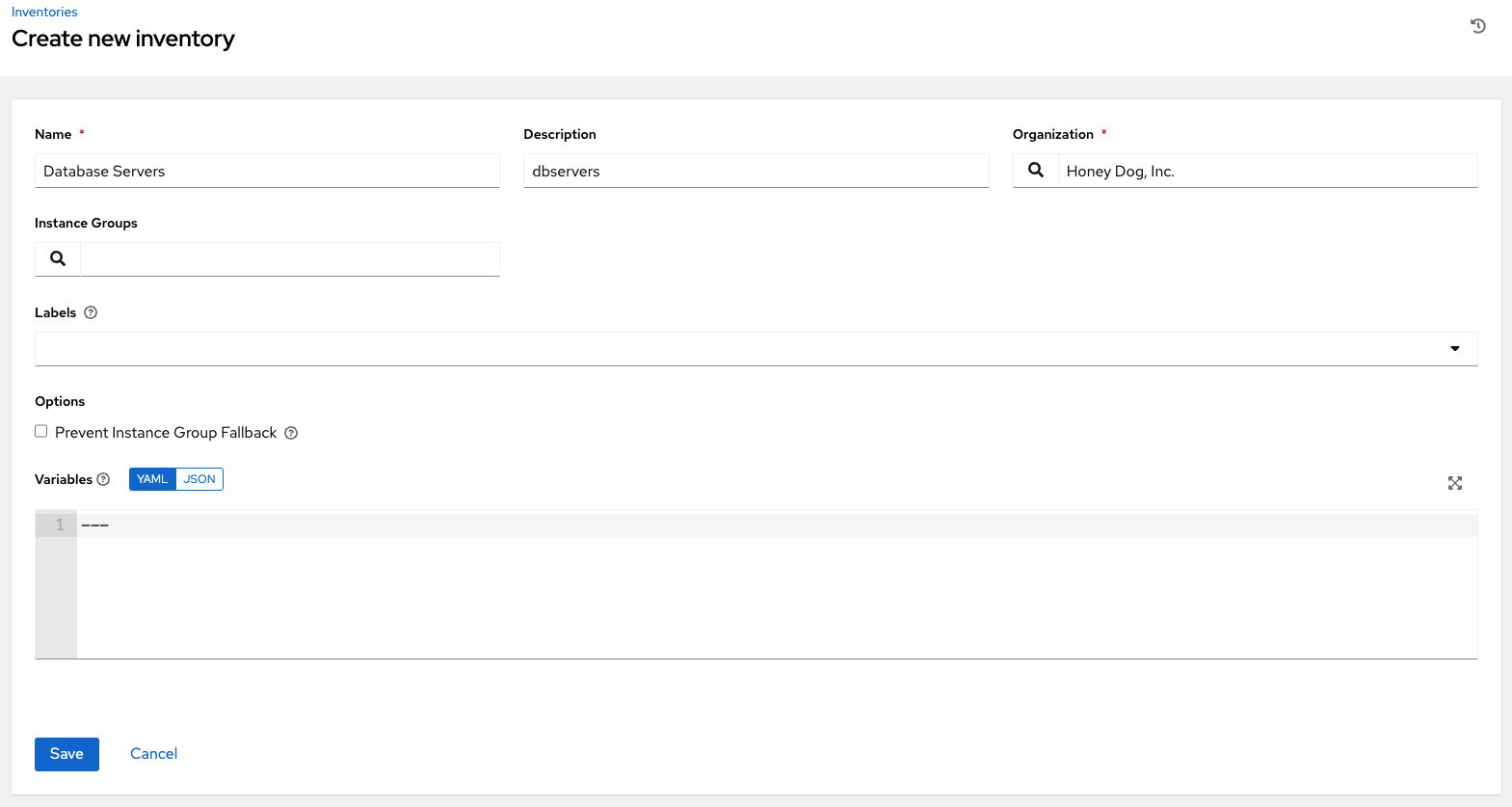
变量(构建的清单的源变量)
变量要应用于此清单中所有主机的变量定义和值。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。
构建的清单的源变量创建组,具体位于数据的
groups键下。它接受 Jinja2 模板语法,为每个主机呈现它,进行True/False评估,如果结果为True,则将主机包含在组中(来自条目的键)。这特别有用,因为您可以将该组名称粘贴到限制字段中,以仅包含该组中的主机。请参阅示例此处。
完成后,点击保存。
保存新清单后,您可以继续配置权限、组、主机、源,并在适用时查看已完成的作业。有关更多说明,请参阅后续部分。
18.4.1. 添加权限
在访问选项卡中,点击添加按钮。
选择要添加的用户或团队,然后点击下一步
通过点击名称旁边的复选框选择列表中的一个或多个用户或团队以将其添加为成员,然后点击下一步。
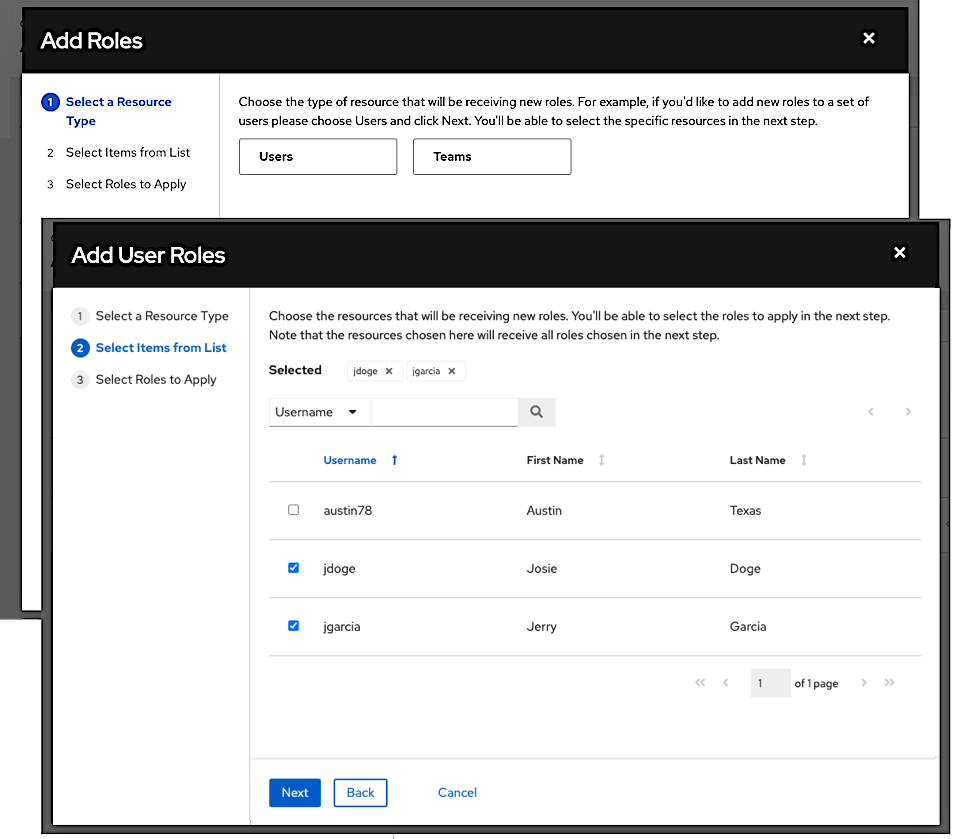
在此示例中,已选择两个用户进行添加。
选择您希望选定的用户或团队具有的角色。请务必向下滚动以查看完整的角色列表。不同的资源具有不同的可用选项。
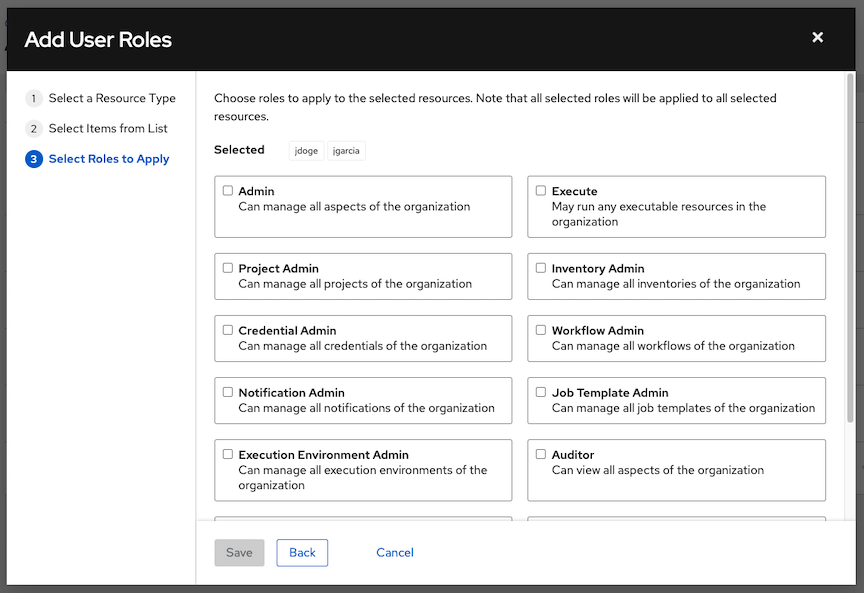
点击保存按钮将角色应用于选定的用户或团队,并将其添加为成员。
“添加用户/团队”窗口关闭以显示为每个用户和团队分配的更新后的角色。
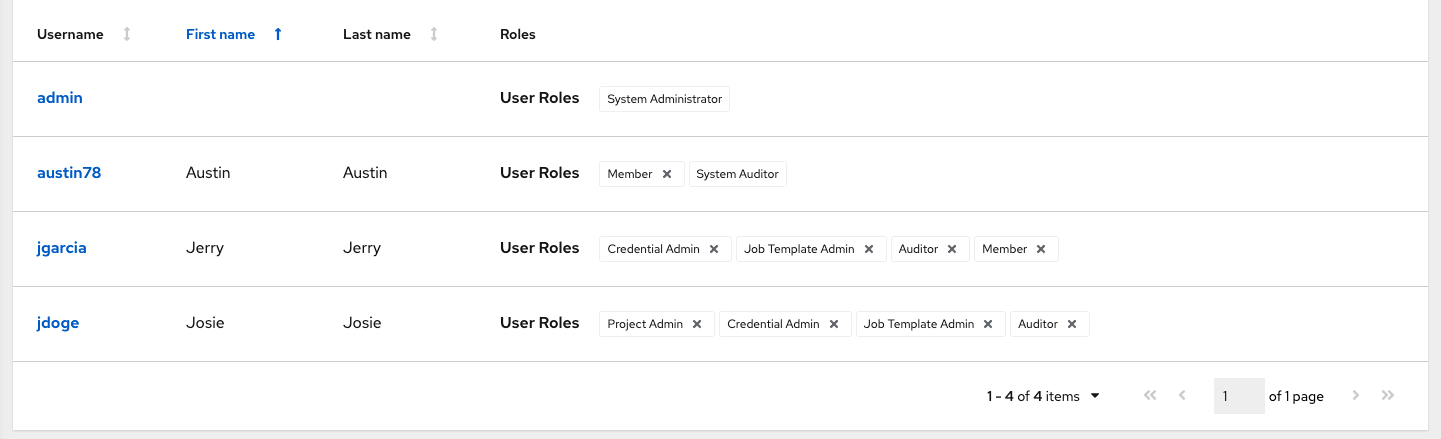
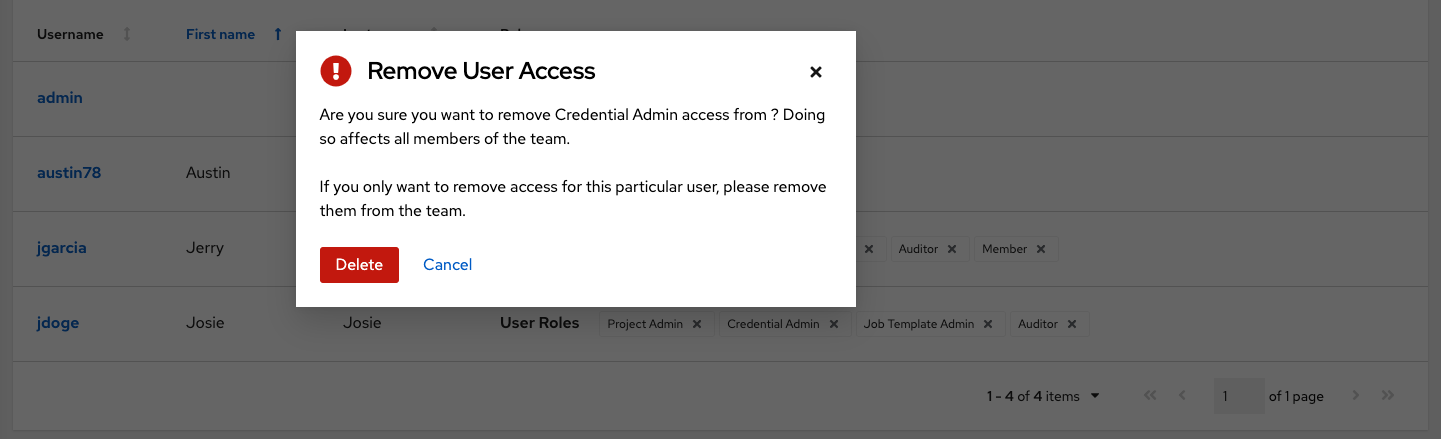
要删除特定用户的角色,请点击其资源旁边的取消关联(x)按钮。
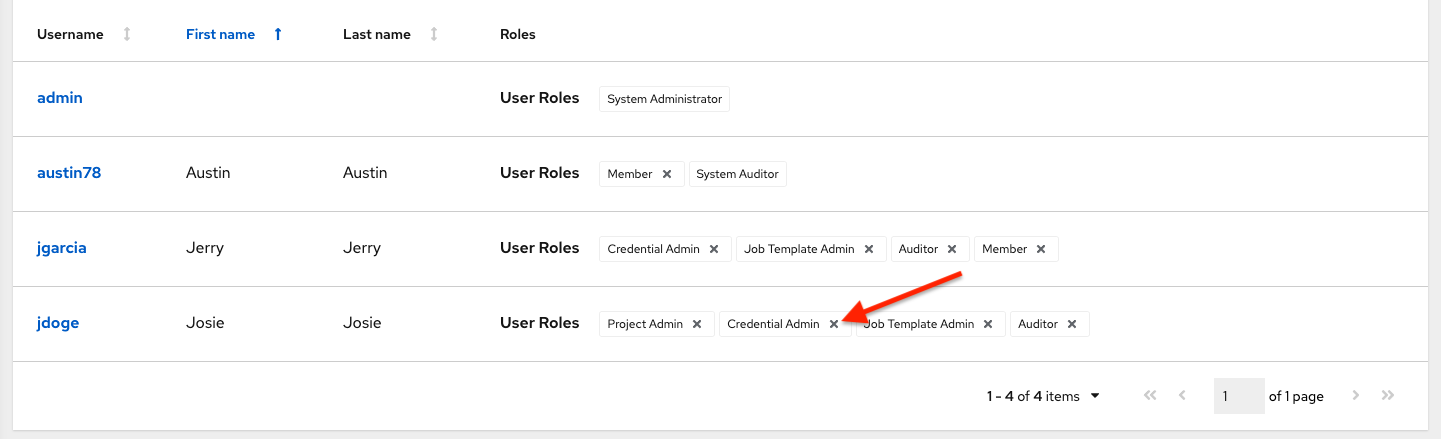
这将启动一个确认对话框,要求您确认取消关联。
18.4.2. 添加组
清单分为组,组可能包含主机和其他组,以及主机。组仅适用于标准清单,并且不能通过智能清单直接配置。您可以通过与标准清单一起使用的主机关联现有组。标准清单有几个可用的操作
创建新组
创建新主机
在选定的清单上运行命令
编辑清单属性
查看组和主机的活动流
获取构建清单的帮助
注意
清单源与组无关。生成的组是顶级组,可能仍然具有子组,并且所有这些生成的组都可能具有主机。
要为清单创建新组
点击添加按钮以打开创建组窗口。
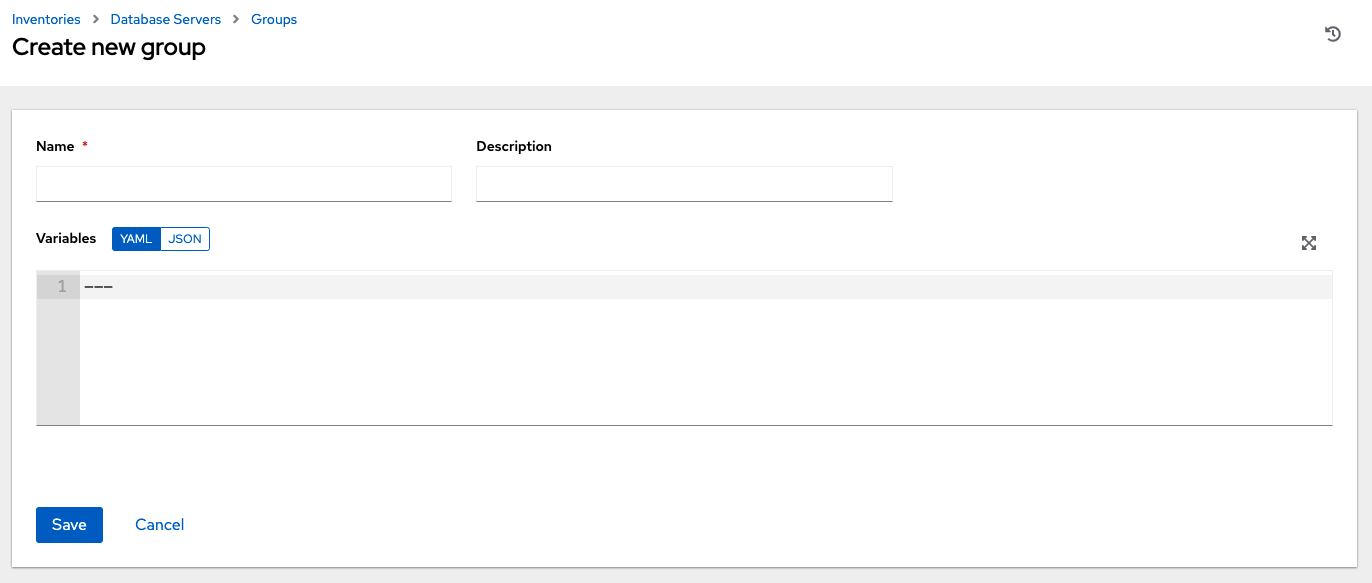
在必填和可选字段中输入相应的详细信息
名称:必填
描述:根据需要输入任意描述(可选)
变量:输入要应用于此组中所有主机的定义和值。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。
完成后,点击保存。
18.4.2.1. 在组内添加组
要在组内添加组
点击相关组选项卡。
点击添加按钮,然后选择是添加配置中已存在的组还是创建新组。
如果要创建新组,请在必填字段和可选字段中输入相应的详细信息
名称:必填
描述:根据需要输入任意描述(可选)
变量:输入要应用于此组中所有主机的定义和值。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。
完成后,点击保存。
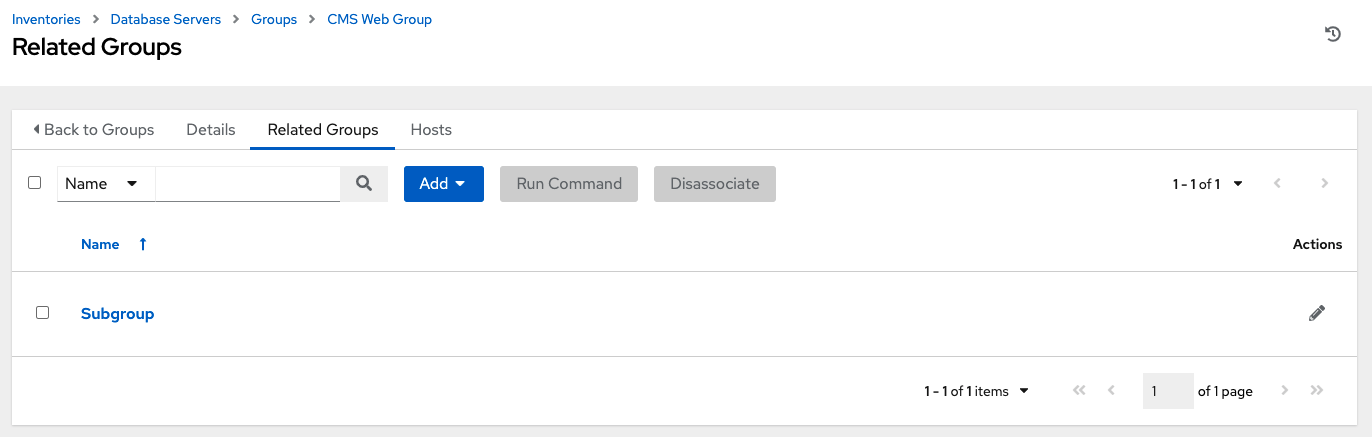
创建组窗口关闭,新创建的组将显示为与其创建目标组关联的组列表中的一个条目。
如果您选择添加现有组,则可用组将显示在单独的选择窗口中。
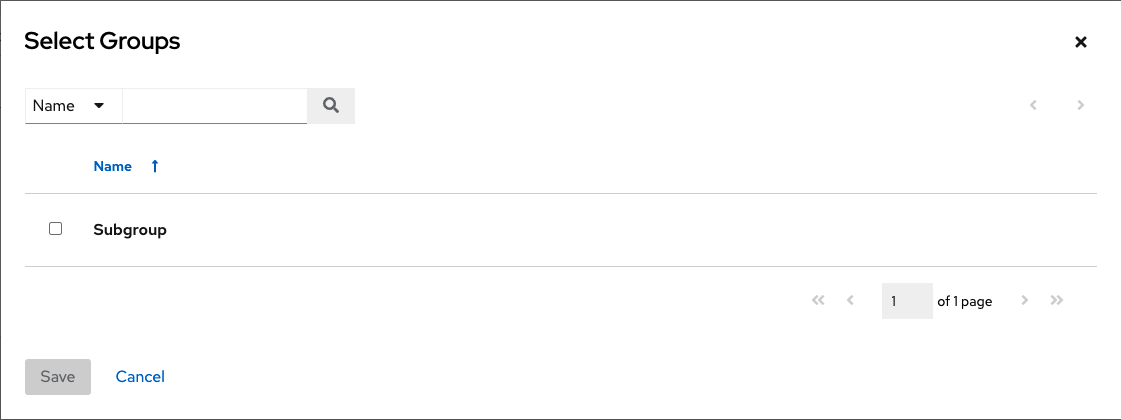
选择组后,它将显示为与该组关联的组列表中的一个条目。
5. 要在子组下配置其他组和主机,请从组列表中点击子组的名称,并重复本节中描述的相同步骤。
18.4.2.2. 查看或编辑清单组
列表视图一次显示所有清单组,或者您可以将其过滤为仅显示根组。如果清单组不是另一个组的子集,则将其视为根组。
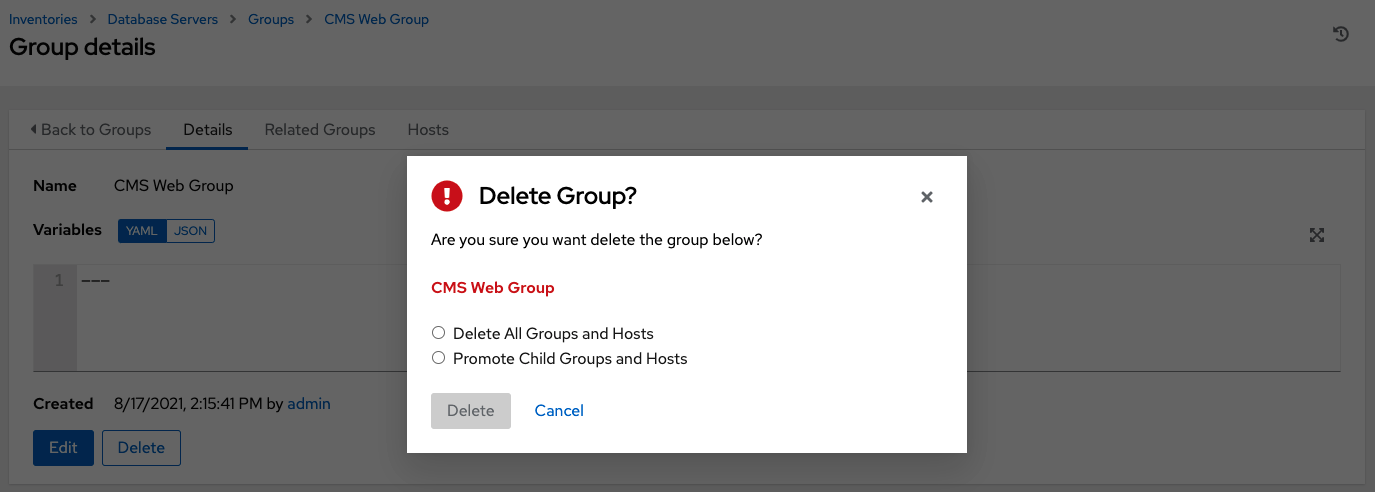
您可能能够删除子组而无需担心依赖项,因为 AWX 将查找依赖项,例如任何子组或主机。如果存在任何依赖项,则会显示一个确认对话框,供您选择是删除根组及其所有子组和主机;还是提升子组,使它们成为顶级清单组,以及它们的主机。
18.4.3. 添加主机
您可以为清单以及组和组内的组配置主机。要配置主机
点击主机选项卡。
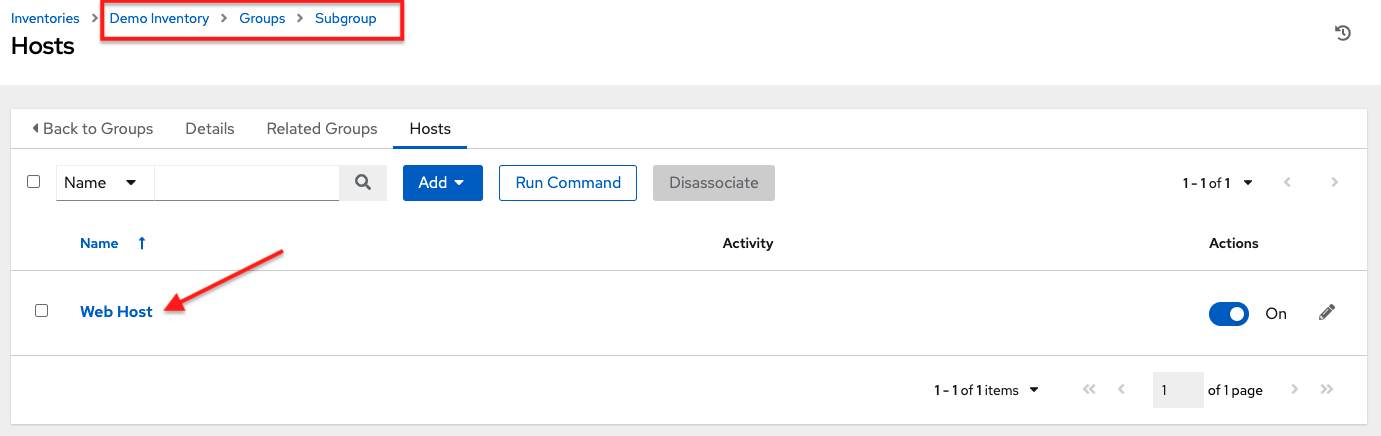
点击添加按钮,然后选择是添加配置中已存在的主机还是创建新主机。
如果要创建新主机,请选择
 按钮以指定是否在运行作业时包含此主机。
按钮以指定是否在运行作业时包含此主机。
在必填和可选字段中输入相应的详细信息
主机名:必填
描述:根据需要输入任意描述(可选)
变量:输入要应用于此组中所有主机的定义和值。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。
完成后,点击保存。
创建主机窗口关闭,新创建的主机将显示为与其创建目标组关联的主机列表中的一个条目。
如果您选择添加现有主机,则可用主机将显示在单独的选择窗口中。
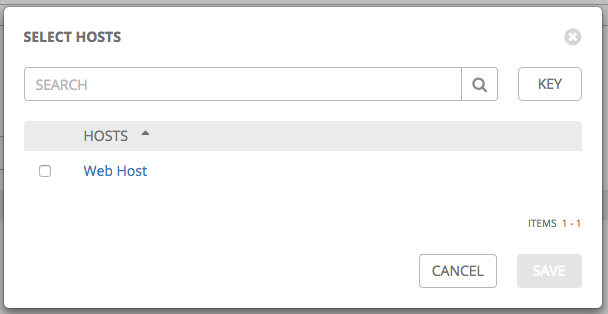
选择主机后,它将显示为主机关联的组列表中的一个条目。您可以从此屏幕取消关联主机,方法是选择主机并点击取消关联按钮。
注意
您也可以从此屏幕运行临时命令。有关更多详细信息,请参阅运行临时命令。
6. 要为主机配置其他组,请从主机列表中点击主机的名称。
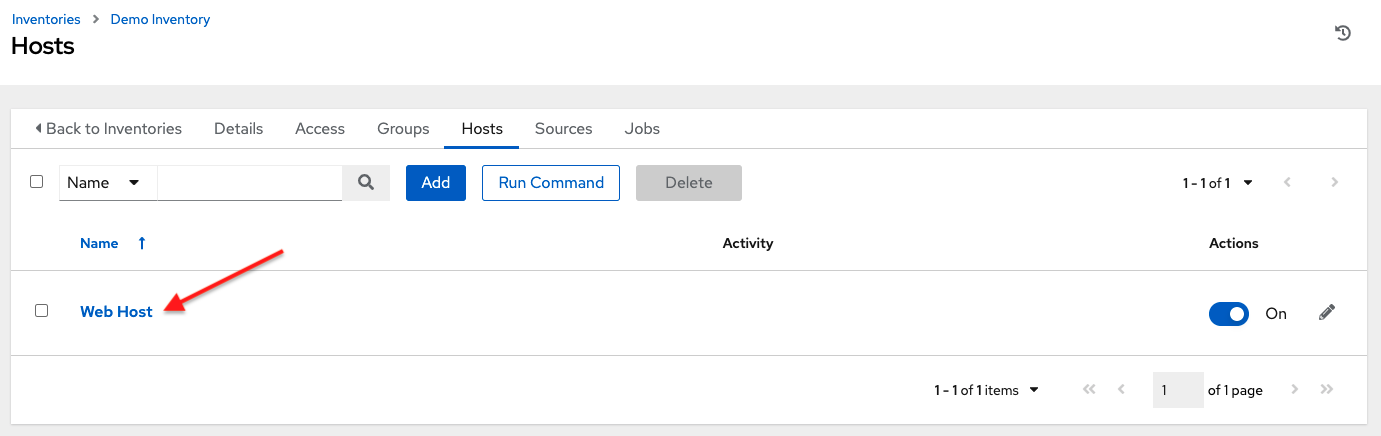
这将打开所选主机的详细信息选项卡。
点击组选项卡以配置主机组。
点击添加按钮将主机与现有组关联。
可用组将显示在单独的选择窗口中。
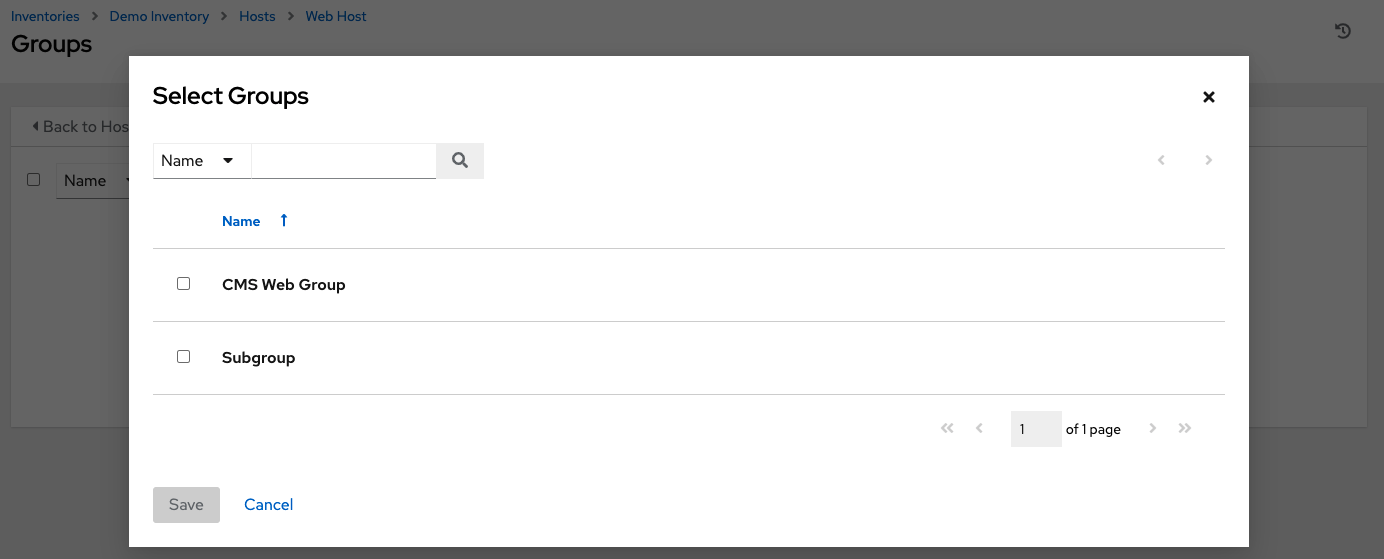
点击选择要与主机关联的组,然后点击保存。
关联组后,它将显示为主机关联的组列表中的一个条目。
如果使用主机运行作业,则可以在主机的已完成作业选项卡中查看有关这些作业的详细信息,并点击展开以查看有关每个作业的详细信息。
注意
您可以使用 API 中新添加的端点/api/v2/bulk/host_create批量创建主机。此端点接受 JSON,您可以指定目标清单以及要添加到清单的主机列表。这些主机在清单中必须是唯一的。要么所有主机都已添加,要么返回错误,指示操作无法完成的原因。使用OPTIONS请求返回相关模式。有关更多信息,请参阅AWX API 指南的参考部分中的批量端点。
18.4.4. 添加源
清单源不与组关联。生成的组是顶级组,可能仍然具有子组,并且所有这些生成的组可能都具有主机。将源添加到清单仅适用于标准清单。智能清单继承与其关联的标准清单的源。要配置清单的源
在您要添加源的清单中,点击源选项卡。
点击添加按钮。
这将打开创建源窗口。
在必填和可选字段中输入相应的详细信息
在完成您选择的清单源所需的信息后,您可以继续选择指定其他常用参数,例如详细程度、主机过滤器和变量。
从详细程度下拉菜单中选择任何清单源的更新作业的适当输出级别。
使用主机过滤器字段指定仅将匹配的主机名导入 AWX。
在启用变量中,指定 AWX 从给定的主机变量字典中检索启用状态。可以使用点表示法将启用变量指定为“foo.bar”,在这种情况下,查找将遍历嵌套字典,等效于:
from_dict.get('foo', {}).get('bar', default)。如果您在启用变量字段中指定了主机变量的字典,则可以提供导入时要启用的值。例如,如果
enabled_var='status.power_state'和enabled_value='powered_on'以及以下主机变量,则主机将被标记为已启用
{ "status": { "power_state": "powered_on", "created": "2020-08-04T18:13:04+00:00", "healthy": true }, "name": "foobar", "ip_address": "192.168.2.1" }如果
power_state的值不是powered_on,则在导入到 AWX 时,主机将被禁用。如果找不到键,则主机将被启用。
所有云清单源都具有以下更新选项
覆盖:如果选中,则之前存在于外部源上但现在已删除的任何主机和组都将从 AWX 清单中删除。未由清单源管理的主机和组将被提升到下一个手动创建的组,或者如果没有手动创建的组可以将其提升到,则它们将保留在清单的“all”默认组中。
如果未选中,则在外部源上找不到的本地子主机和组将不受清单更新过程的影响。
覆盖变量:如果选中,则将删除子组和主机的所有变量,并替换为在外部源上找到的变量。如果未选中,则将执行合并,将本地变量与在外部源上找到的变量结合起来。
启动时更新:每次使用此清单运行作业时,都在执行作业任务之前从选定的源刷新清单。为了避免如果作业生成速度快于清单同步速度而导致作业溢出,选择此选项允许您配置缓存超时以将先前的清单同步缓存一定秒数。
“启动时更新”设置指的是项目和清单的依赖项系统,它不会专门排除两个作业同时运行。如果指定了缓存超时,则会创建第二个作业的依赖项,它使用第一个作业生成的项目和清单更新。然后,这两个作业都在继续之前等待该项目和/或清单更新完成。如果它们是不同的作业模板,那么如果系统有能力这样做,它们就可以同时开始并运行。如果您打算将 AWX 的配置回调功能与动态清单源一起使用,则应为清单组设置启动时更新。
如果您同步使用具有设置的启动时更新的项目的清单源,则项目可能会在清单更新开始之前自动更新(根据缓存超时规则)。
您可以创建一个使用从与模板使用的相同项目获取源的清单的作业模板。在这种情况下,项目将更新,然后清单将更新(如果更新尚未进行,或者缓存超时尚未过期)。
查看您的条目和选择,并在完成后点击保存。这允许您配置其他详细信息,例如计划和通知。
要配置与此清单源关联的计划,请点击计划选项卡。
如果计划已设置;查看、编辑或启用/禁用您的计划首选项。
如果计划尚未设置,请参阅计划以获取更多信息。
注意
通知选项卡仅在保存新创建的源后才会出现。
要配置源的通知,请点击通知选项卡。
查看您的条目和选择,并在完成后点击保存。
定义源后,它将显示为与清单关联的源列表中的一个条目。从源选项卡,您可以对单个源执行同步,或一次同步所有源。您还可以执行其他操作,例如计划同步过程,以及编辑或删除源。
18.4.4.1. 清单源
选择一个与主机可以输入的主机类型匹配的源
18.4.4.1.1. 源自项目
源自项目的清单表示它使用与其关联的项目的 SCM 类型。例如,如果项目的源自 GitHub,则清单将使用相同的源。
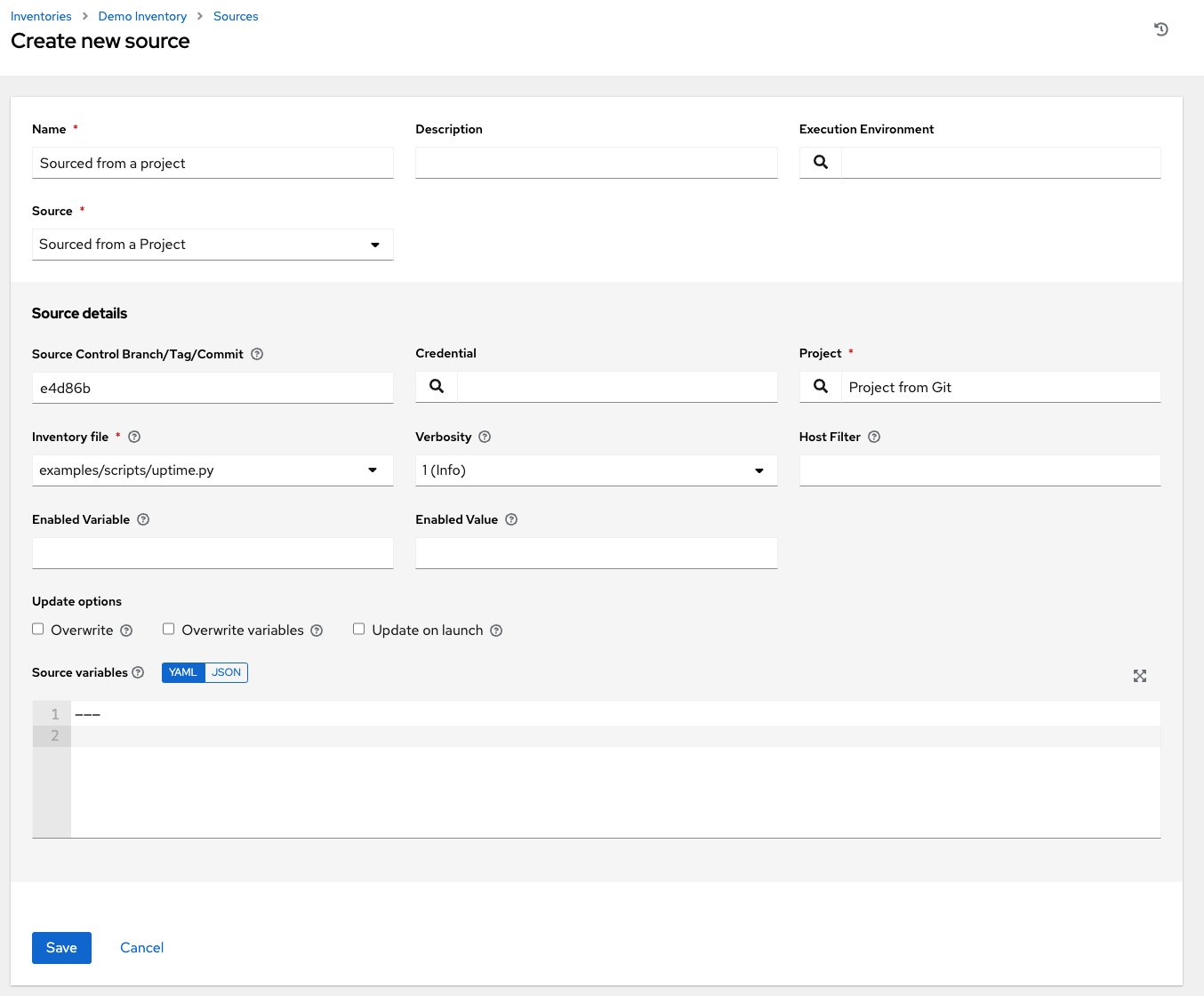
要配置项目源清单,请从“源”字段中选择**源自项目**。
“创建源”窗口将扩展其他字段。输入以下详细信息
**源代码分支/标签/提交**:可选地输入要检出的源代码管理(Git 或 Subversion)中的 SCM 分支、标签、提交哈希、任意引用或修订版本号(如果适用)。除非您还在下一个字段中提供自定义 refspec,否则某些提交哈希和引用可能不可用。如果留空,则默认为 HEAD,即此项目的最后检出的分支/标签/提交。
仅当源项目选中了**允许分支覆盖**选项时,此字段才会显示。

**凭据**:可选地指定要用于此源的凭据。
**项目**:必填。预填充默认项目,否则,指定此清单用作其源的项目。单击
**清单文件**:必填。选择与源项目关联的清单文件。如果尚未填充,则可以在下拉菜单中的文本字段中键入它以过滤无关的文件类型。除了平面文件清单之外,您还可以指向目录或清单脚本。
您可以选择性地指定详细程度、主机过滤器、启用的变量/值和更新选项,如添加源的主要过程中所述。
为了传递到自定义清单脚本,您可以在**环境变量**字段中选择性地设置环境变量。您也可以将清单脚本放在源代码控制中,然后从项目中运行它。有关详细信息,请参阅《AWX 管理指南》中的清单文件导入。
注意
如果您要从 SCM 执行自定义清单脚本,请确保您在 upstream 源代码控制中的脚本上设置了执行位(即chmod +x)。如果不这样做,AWX 将在执行时抛出[Errno 13] Permission denied错误。
18.4.4.1.2. Amazon Web Services EC2
要配置 AWS EC2 源清单,请从“源”字段中选择**Amazon EC2**。
“创建源”窗口将扩展其他字段。输入以下详细信息
**凭据**:可选地从现有的 AWS 凭据中选择(有关更多信息,请参阅凭据)。
如果 AWX 在分配了 IAM 角色的 EC2 实例上运行,则可以省略凭据,并改为使用实例元数据中的安全凭据。有关使用 IAM 角色的更多信息,请参阅Amazon 上的 IAM_Roles_for_Amazon_EC2 文档。
您可以选择性地指定详细程度、主机过滤器、启用的变量/值和更新选项,如添加源的主要过程中所述。
使用**源变量**字段覆盖
aws_ec2清单插件使用的变量。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。有关这些变量的详细说明,请查看aws_ec2 清单插件文档。
注意
如果您只使用include_filters,则 AWS 插件始终返回所有主机。要正确使用此功能,or上的第一个条件必须在filters上,然后在include_filters列表上构建其余的OR条件。
18.4.4.1.3. Google Compute Engine
要配置 Google 源清单,请从“源”字段中选择**Google Compute Engine**。
“创建源”窗口将扩展必填的**凭据**字段。从现有的 GCE 凭据中选择。有关更多信息,请参阅凭据。
您可以选择性地指定详细程度、主机过滤器、启用的变量/值和更新选项,如添加源的主要过程中所述。
使用**源变量**字段覆盖
gcp_compute清单插件使用的变量。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。有关这些变量的详细说明,请查看gcp_compute 清单插件文档。
18.4.4.1.4. Microsoft Azure 资源管理器
要配置 Azure 资源管理器源清单,请从“源”字段中选择**Microsoft Azure 资源管理器**。
“创建源”窗口将扩展必填的**凭据**字段。从现有的 Azure 凭据中选择。有关更多信息,请参阅凭据。
您可以选择性地指定详细程度、主机过滤器、启用的变量/值和更新选项,如添加源的主要过程中所述。
使用**源变量**字段覆盖
azure_rm清单插件使用的变量。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。有关这些变量的详细说明,请查看azure_rm 清单插件文档。
18.4.4.1.5. VMware vCenter
要配置 VMWare 源清单,请从“源”字段中选择**VMware vCenter**。
“创建源”窗口将扩展必填的**凭据**字段。从现有的 VMware 凭据中选择。有关更多信息,请参阅凭据。
您可以选择性地指定详细程度、主机过滤器、启用的变量/值和更新选项,如添加源的主要过程中所述。
使用**源变量**字段覆盖
vmware_inventory清单插件使用的变量。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。有关这些变量的详细说明,请查看vmware_inventory 清单插件。
从 Ansible 2.9 开始,VMWare 属性已从小写更改为驼峰式大小写。AWX 为顶级键提供了别名,但嵌套属性中的小写键已停止使用。有关从 Ansible 2.9 开始的有效和受支持属性列表,请参阅VMware 动态清单插件中的虚拟机属性。
18.4.4.1.6. Red Hat Satellite 6
要配置 Red Hat Satellite 源清单,请从“源”字段中选择**Red Hat Satellite**。
“创建源”窗口将扩展必填的**凭据**字段。从现有的 Satellite 凭据中选择。有关更多信息,请参阅凭据。
您可以选择性地指定详细程度、主机过滤器、启用的变量/值和更新选项,如添加源的主要过程中所述。
使用**源变量**字段指定 foreman 清单源使用的参数。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。有关这些变量的详细说明,请参阅 Ansible 文档中的theforeman.foreman.foreman – Foreman 清单源。
如果您遇到 AWX 清单没有 Satellite 的“相关组”的问题,您可能需要在清单源中定义这些变量。有关详细信息,请参阅《AWX 安装和参考指南》中Red Hat Satellite 6的清单插件模板示例。
18.4.4.1.7. Red Hat Insights
要配置 Red Hat Insights 源清单,请从“源”字段中选择**Red Hat Insights**。
“创建源”窗口将扩展必填的**凭据**字段。从现有的 Insights 凭据中选择。有关更多信息,请参阅凭据。
您可以选择性地指定详细程度、主机过滤器、启用的变量/值和更新选项,如添加源的主要过程中所述。
使用**源变量**字段覆盖
insights清单插件使用的变量。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。有关这些变量的详细说明,请查看insights 清单插件。
18.4.4.1.8. OpenStack
要配置 OpenStack 源清单,请从“源”字段中选择**OpenStack**。
“创建源”窗口将扩展必填的**凭据**字段。从现有的 OpenStack 凭据中选择。有关更多信息,请参阅凭据。
您可以选择性地指定详细程度、主机过滤器、启用的变量/值和更新选项,如添加源的主要过程中所述。
使用**源变量**字段覆盖
openstack清单插件使用的变量。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。有关这些变量的详细说明,请查看 Ansible 集合文档中的openstack 清单插件。
18.4.4.1.9. Red Hat Virtualization
要配置 Red Hat Virtualization 来源的清单,请从“源”字段中选择**Red Hat Virtualization**。
“创建源”窗口将展开,其中包含必需的**凭据**字段。从现有的 Red Hat Virtualization 凭据中选择。有关更多信息,请参阅凭据。
您可以选择性地指定详细程度、主机过滤器、启用的变量/值和更新选项,如添加源的主要过程中所述。
使用**源变量**字段覆盖
ovirt清单插件使用的变量。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。有关这些变量的详细说明,请查看ovirt 清单插件。
注意
Red Hat Virtualization (ovirt) 清单源请求默认情况下是安全的。要更改此默认设置,请在 source_variables 中将键 ovirt_insecure 设置为**true**,此设置仅在清单源的 /api/v2/inventory_sources/N/ 端点的 API 详细信息中可用。
18.4.4.1.10. Red Hat Ansible Automation Platform
要配置此类型的来源清单,请从“源”字段中选择**Red Hat Ansible Automation Platform**。
“创建源”窗口将展开,其中包含必需的**凭据**字段。从现有的 Ansible Automation Platform 凭据中选择。有关更多信息,请参阅凭据。
您可以选择性地指定详细程度、主机过滤器、启用的变量/值和更新选项,如添加源的主要过程中所述。
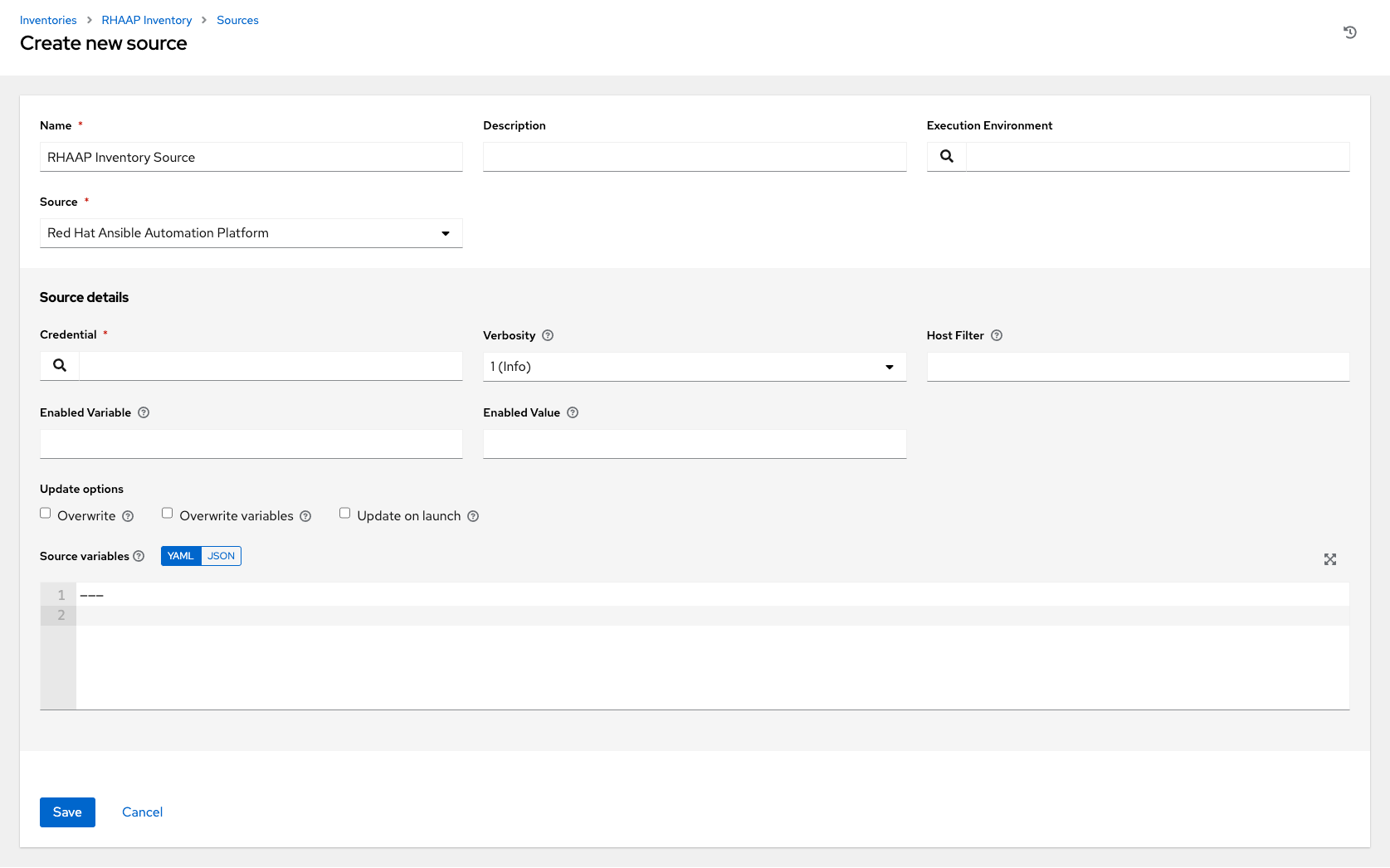
使用**源变量**字段覆盖
controller清单插件使用的变量。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。
18.4.4.1.11. Terraform State
此清单源使用来自cloud.terraform 集合的terraform_state 清单插件。该插件将解析 terraform 状态文件,并为 AWS EC2、GCE 和 Azure 实例添加主机。
要配置此类型的来源清单,请从“源”字段中选择**Terraform State**。
“创建新源”窗口将展开,其中包含必需的**凭据**字段。从现有的 Terraform 后端凭据中选择。有关更多信息,请参阅Terraform 后端配置。
您可以选择性地指定详细程度、主机过滤器、启用的变量/值和更新选项,如添加源的主要过程所述。对于 Terraform,请启用**覆盖**和**启动时更新**选项。
使用**源变量**字段覆盖
terraform清单插件使用的变量。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。有关这些变量的更多信息,请参阅terraform_state 文件以获取详细信息。
变量
backend_type是 Terraform 状态清单插件所需的。这应该与 Terraform 后端凭据中配置的远程后端匹配,以下是一个 Amazon S3 后端的示例--- backend_type: s3
在**执行环境**字段中输入包含 Terraform 二进制文件的执行环境。这是清单插件运行读取 Terraform 状态文件中清单数据的 Terraform 命令所必需的。请参阅包含 Terraform 二进制文件示例执行环境配置的Terraform EE 自述文件。
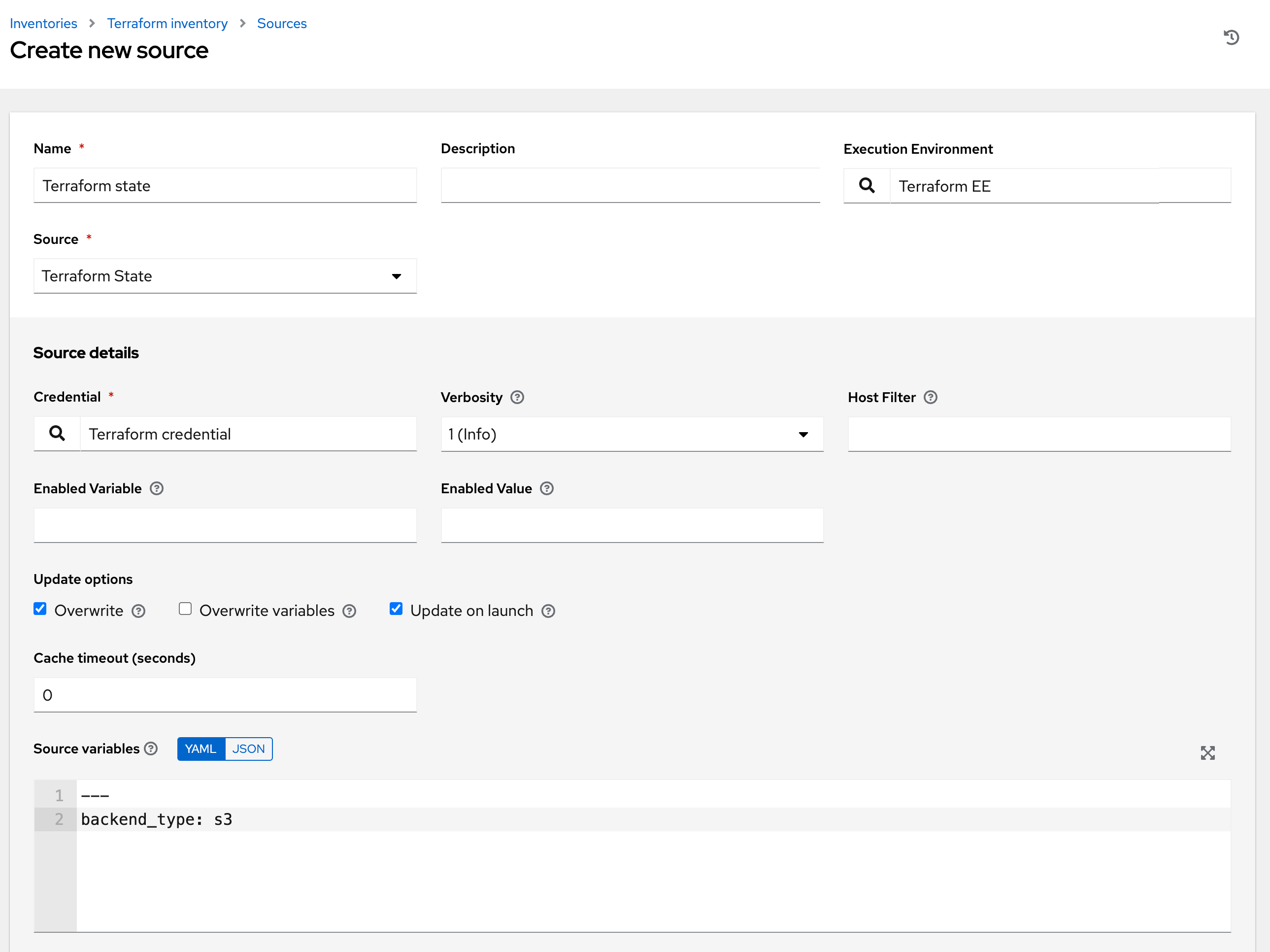
要添加 AWS EC2、GCE 和 Azure 实例的主机,后端中的 Terraform 状态文件必须包含已部署到 EC2、GCE 或 Azure 的资源的状态。请参阅每个 Terraform 提供程序各自的文档以配置实例。
18.4.4.1.12. OpenShift Virtualization
此清单源使用能够部署 OpenShift (OCP) 虚拟化的集群。要配置 OCP 虚拟化,需要在特定命名空间中部署虚拟机,以及 OpenShift 或 Kubernetes API Bearer Token 凭据。
要配置此类型的来源清单,请从“源”字段中选择**OpenShift Virtualization**。
“创建新源”窗口将展开,其中包含必需的**凭据**字段。从现有的 Kubernetes API Bearer Token 凭据中选择。有关更多信息,请参阅OpenShift 或 Kubernetes API Bearer Token。在此示例中,使用
cmv2.engineering.redhat.com凭据。您可以选择性地指定详细程度、主机过滤器、启用的变量/值和更新选项,如添加源的主要过程中所述。
使用**源变量**字段覆盖
kubernetes清单插件使用的变量。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。有关这些变量的更多信息,请参阅kubevirt.core.kubevirt 清单源 文档以获取详细信息。
在下面的示例中,使用
connections变量指定对集群中特定命名空间的访问。--- connections: - namespaces: - hao-test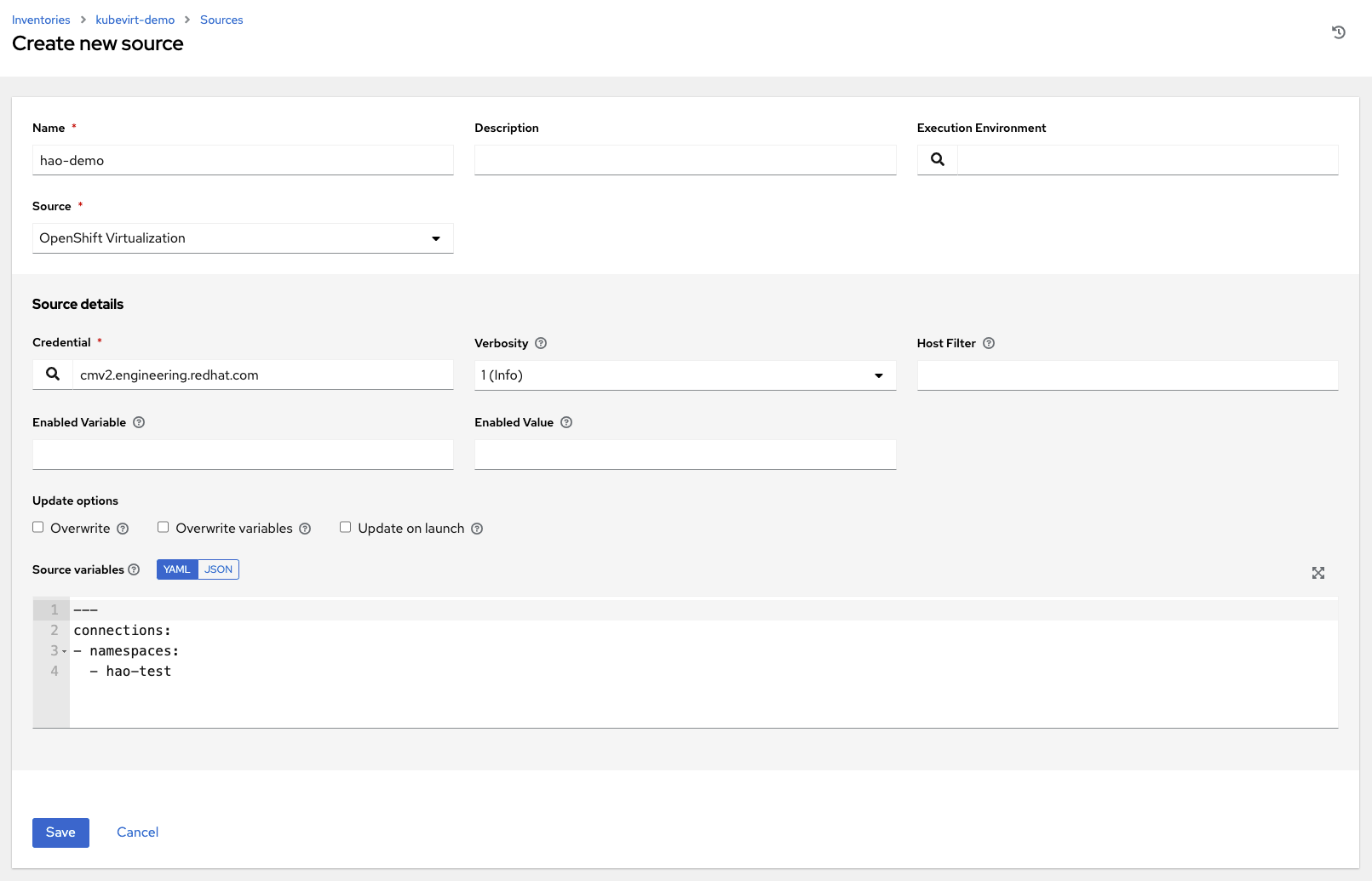
保存配置并点击**同步**按钮以同步清单。
18.4.4.2. 导出旧清单脚本
尽管已删除自定义清单脚本 API,但脚本仍保存在数据库中。本节中描述的命令允许您以适合您随后检入源代码管理的格式恢复脚本。用法如下所示
$ awx-manage export_custom_scripts --filename=my_scripts.tar
Dump of old custom inventory scripts at my_scripts.tar
利用输出
$ mkdir my_scripts
$ tar -xf my_scripts.tar -C my_scripts
脚本的命名为 _<pk>__<name>。这是用于项目文件夹的命名方案。
$ ls my_scripts
_10__inventory_script_rawhook _19__ _30__inventory_script_listenhospital
_11__inventory_script_upperorder _1__inventory_script_commercialinternet45 _4__inventory_script_whitestring
_12__inventory_script_eastplant _22__inventory_script_pinexchange _5__inventory_script_literaturepossession
_13__inventory_script_governmentculture _23__inventory_script_brainluck _6__inventory_script_opportunitytelephone
_14__inventory_script_bottomguess _25__inventory_script_buyerleague _7__inventory_script_letjury
_15__inventory_script_wallisland _26__inventory_script_lifesport _8__random_inventory_script_
_16__inventory_script_wallisland _27__inventory_script_exchangesomewhere _9__random_inventory_script_
_17__inventory_script_bidstory _28__inventory_script_boxchild
_18__p _29__inventory_script_wearstress
每个文件包含一个脚本。脚本可以是 bash/python/ruby/more,因此不包含扩展名。它们都是直接可执行的(假设脚本有效)。如果执行脚本,它会转储清单数据。
$ ./my_scripts/_11__inventory_script_upperorder
{"group_\ud801\udcb0\uc20e\u7b0e\ud81c\udfeb\ub12b\ub4d0\u9ac6\ud81e\udf07\u6ff9\uc17b": {"hosts":
["host_\ud821\udcad\u68b6\u7a51\u93b4\u69cf\uc3c2\ud81f\uddbe\ud820\udc92\u3143\u62c7",
"host_\u6057\u3985\u1f60\ufefb\u1b22\ubd2d\ua90c\ud81a\udc69\u1344\u9d15",
"host_\u78a0\ud820\udef3\u925e\u69da\ua549\ud80c\ude7e\ud81e\udc91\ud808\uddd1\u57d6\ud801\ude57",
"host_\ud83a\udc2d\ud7f7\ua18a\u779a\ud800\udf8b\u7903\ud820\udead\u4154\ud808\ude15\u9711",
"host_\u18a1\u9d6f\u08ac\u74c2\u54e2\u740e\u5f02\ud81d\uddee\ufbd6\u4506"], "vars": {"ansible_host": "127.0.0.1", "ansible_connection":
"local"}}}
您可以使用 ansible-inventory 验证功能。这应该提供相同的数据,但格式已重新格式化。
$ ansible-inventory -i ./my_scripts/_11__inventory_script_upperorder --list --export
在上面的示例中,您可以 cd 到 my_scripts,然后发出 git init 命令,添加所需的脚本,将其推送到源代码管理,然后在 AWX 用户界面中创建一个 SCM 清单源。
有关同步或使用自定义清单脚本的更多信息,请参阅《AWX 管理指南》中的清单文件导入。
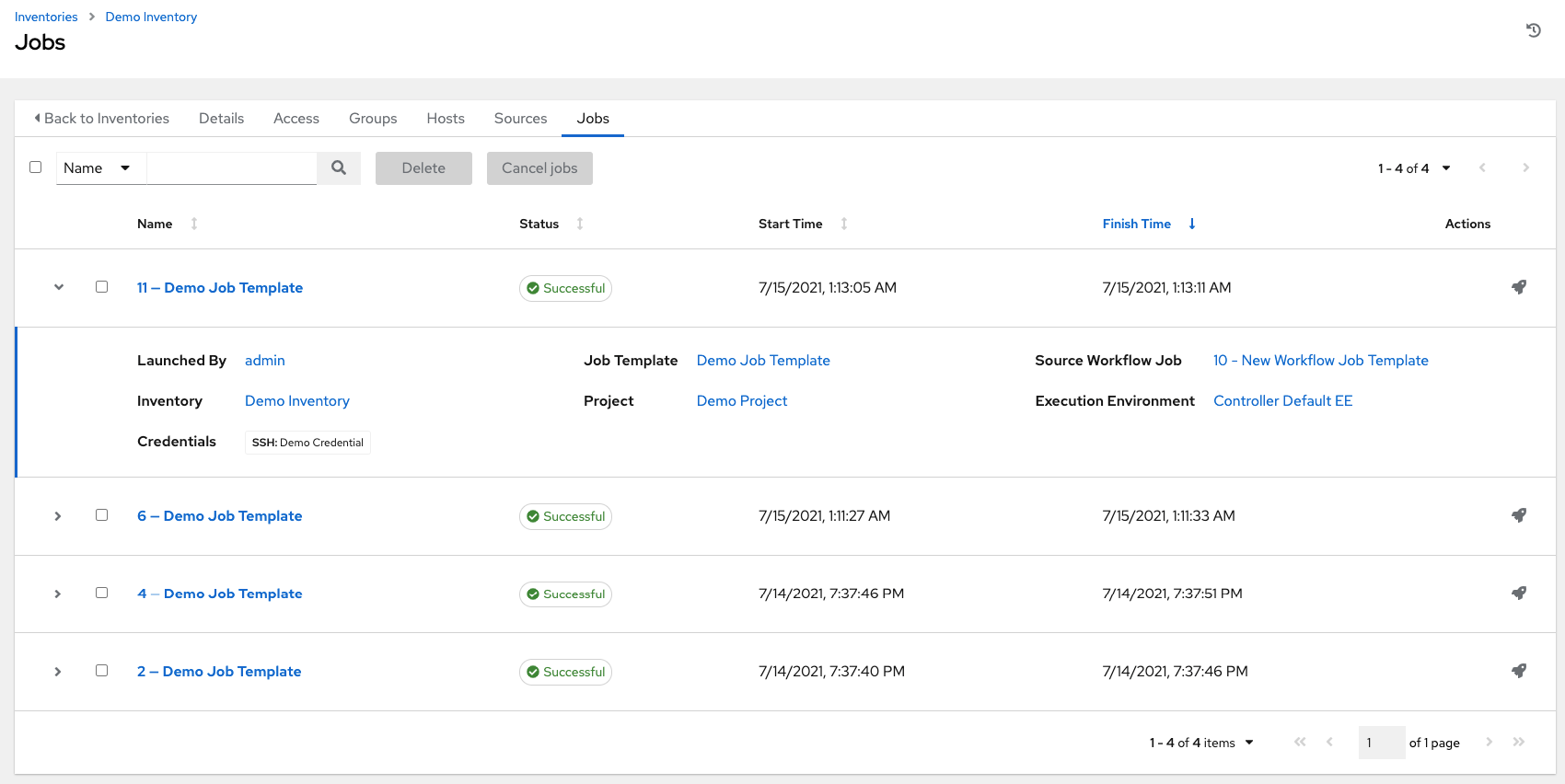
18.4.5. 查看已完成的作业
如果清单用于运行作业,则可以在清单的**已完成作业**选项卡中查看有关这些作业的详细信息,并点击**展开**以查看有关每个作业的详细信息。
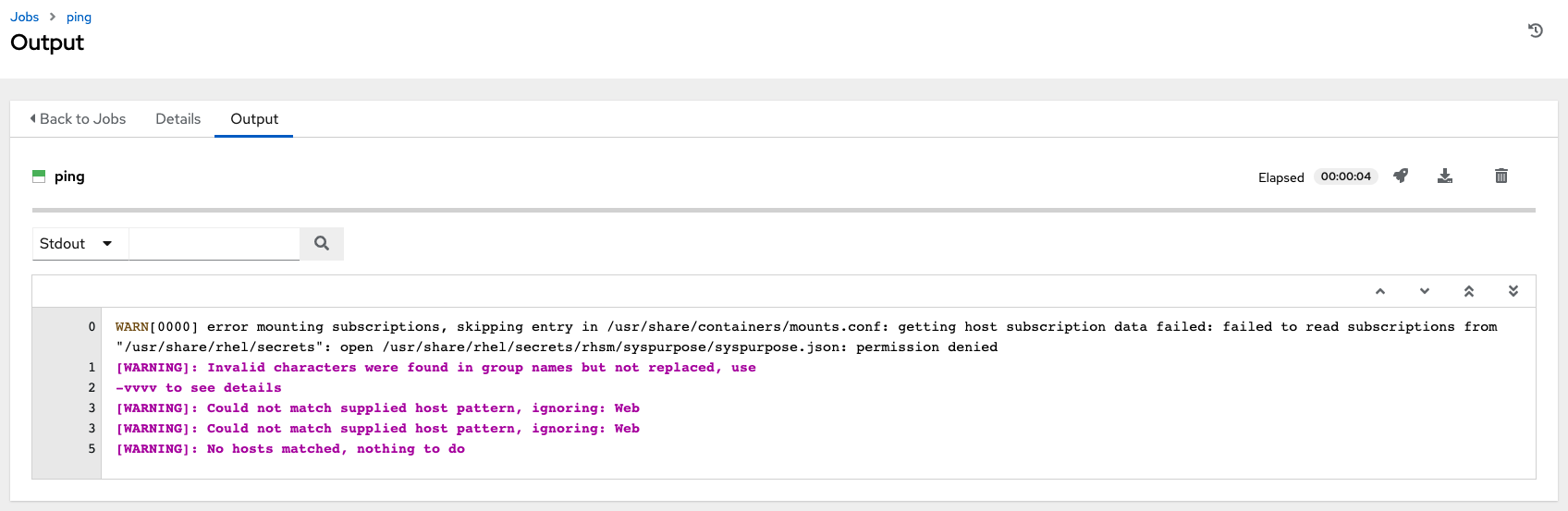
18.5. 运行临时命令
要运行临时命令
从主机或组列表中选择一个清单源。清单源可以是单个组或主机、多个主机的选择或多个组的选择。
点击**运行命令**按钮。
“运行命令”窗口将打开。
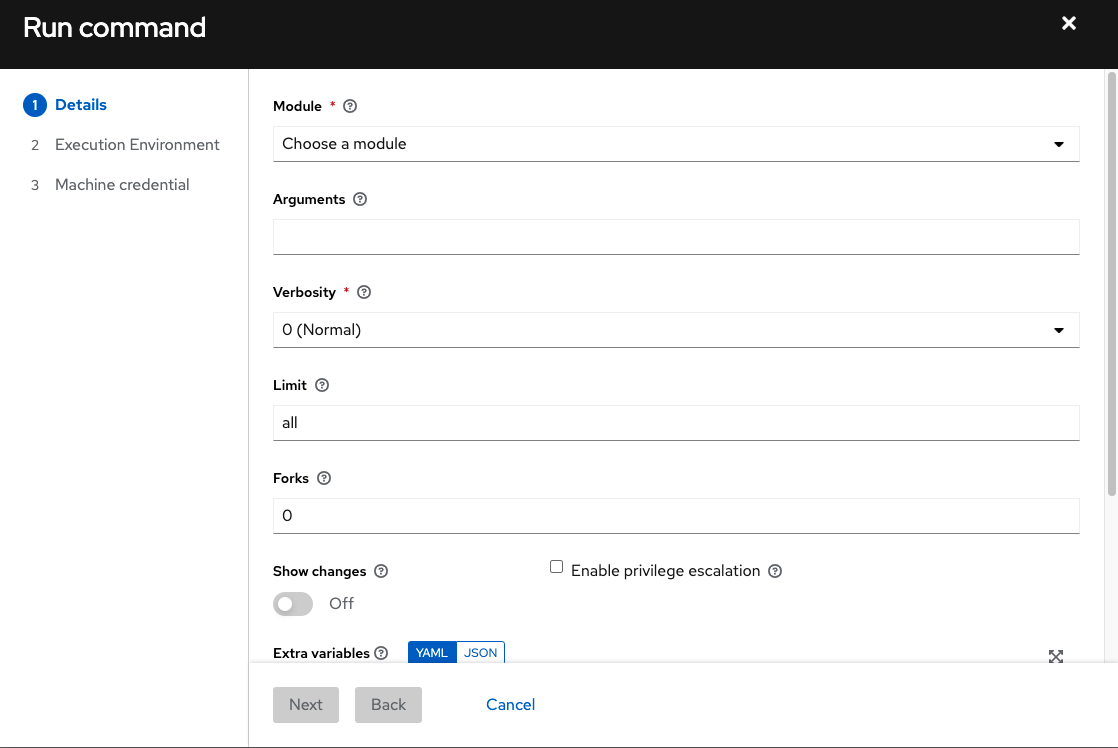
输入以下字段的详细信息
**模块**:选择 AWX 支持针对其运行命令的模块之一。
command
apt_repository
mount
win_service
shell
apt_rpm
ping
win_updates
yum
service
selinux
win_group
apt
group
setup
win_user
apt_key
user
win_ping
**参数**:提供要与所选模块一起使用的参数。
**限制**:输入用于定位清单中主机的限制。要定位清单中的所有主机,请输入
all或*,或保留字段为空。这将自动填充在点击启动按钮之前在先前视图中选择的任何内容。**机器凭据**:选择访问远程主机以运行命令时要使用的凭据。选择包含 Ansbile 需要登录远程主机所需的用户名和 SSH 密钥或密码的凭据。
**详细程度**:选择标准输出的详细程度级别。
**分叉**:如果需要,选择执行命令时要使用的并行或同时进程数。
**显示更改**:选择以启用在标准输出中显示 Ansible 更改。默认值为关闭。
**启用权限提升**:如果启用,则以管理员权限运行剧本。这相当于将
--become选项传递给ansible命令。**额外变量**:提供在运行此清单时要应用的额外命令行变量。使用 JSON 或 YAML 语法输入变量。使用单选按钮在两者之间切换。
点击**下一步**以选择要针对其运行临时命令的执行环境。
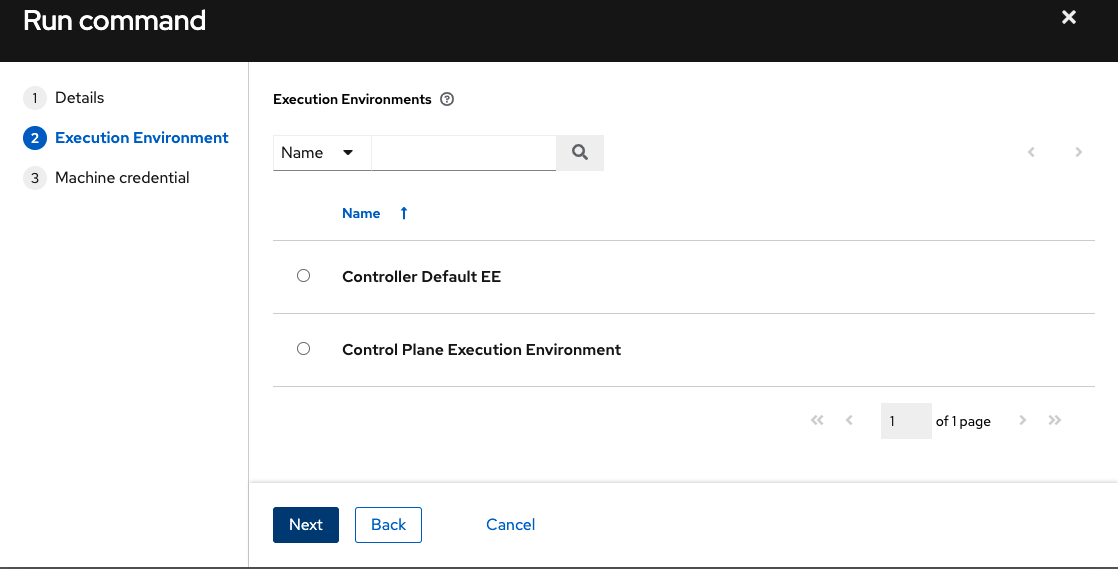
点击**下一步**以选择要使用的凭据,然后点击**启动**按钮。
结果显示在模块作业窗口的**输出**选项卡中。