
13. 提升 AWX 性能
本节旨在提供有关调整 AWX 以提高性能和可扩展性的指南。
13.1. 性能改进
AWX 带来了多项改进,支持 AWX 的大规模部署。在支持更多并发作业的工作负载方面取得了重大进展。过去,存在过多的数据库连接问题,在数千个待处理和正在运行的作业时出现作业调度问题,以及在控制节点容量接近 100% 时成功启动作业的问题。
此外,默认情况下已经进行了更改,以利用较大型控制节点上可用的 CPU 容量。这意味着那些配置了较大控制节点并希望运行数千个并发作业的客户将在本版本中看到多项改进。
13.1.1. 垂直扩展改进
控制节点负责处理作业的输出并将它们写入数据库。执行此操作的过程称为回调接收器。回调接收器具有可配置的 worker 数量,由设置 JOB_EVENT_WORKERS 控制。过去,此设置的默认值始终为 4,无论节点的 CPU 或内存容量如何。现在,在传统的虚拟机中,JOB_EVENT_WORKERS 将设置为与 CPU 数量相同,如果该数量大于 4。这意味着那些配置了较大控制节点的管理员将看到这些节点在处理作业创建的作业输出方面具有更大的能力,而无需手动调整 JOB_EVENT_WORKERS。
13.1.2. 作业调度改进
当作业通过计划、工作流、UI 或 API 创建时,它们首先在“待处理”状态下创建。为了确定何时何地运行此作业,一个名为“任务管理器”的后台任务会收集所有待处理和正在运行的作业,并确定哪里有可用容量来运行作业。在 AWX 的先前版本中,随着待处理和正在运行的作业数量的增加,调度速度变慢,并且任务管理器容易在没有任何进展的情况下超时。这种情况表现出数千个待处理作业、可用容量但没有作业启动的症状。
作业调度器中的优化使调度速度更快,并且还提供了保障措施,以更好地确保调度器即使在接近超时时也能提交其进度。此外,以前在任务管理器中阻止其进度的工作已分离到由调度器执行的单独的非阻塞工作单元中。
13.1.3. 数据库资源使用改进
正在运行的作业对数据库连接的使用已大大减少,这消除了对并发运行作业的先前限制,并减少了对 PostgreSQL 内存消耗的压力。
AWX 中的每个作业在启动该进程的控制节点上都有一个 worker 进程,称为调度 worker,它通过 Receptor 将工作提交到执行节点,并消耗作业的输出,并将输出放入 Redis 队列,以便回调接收器序列化输出并将输出写入数据库作为作业事件。
调度 worker 还负责注意到作业是否已被用户取消,以便随后取消 Receptor 工作单元。过去,worker 每个作业维护多个打开的数据库连接。这导致了两个主要问题。
当同时运行的作业超过 350 个时,应用程序将开始遇到尝试打开新数据库连接(用于 API 调用或其他基本进程)的错误,除非用户增加了最大连接数。
即使空闲连接也会消耗内存。例如,在 AWS 进行的实验中,空闲连接到 PostgreSQL 被证明至少消耗了 1.5 MB 的内存。因此,如果 AWX 管理员希望支持运行 2,000 个并发作业,这可能会导致 PostgreSQL 上仅空闲连接就消耗 9GB 的内存。
调度进程在作业启动后会关闭数据库连接。这意味着现在并发运行的作业数量不再受最大数据库连接数的限制,并且极大地降低了过度使用 PostgreSQL 内存的风险。
13.1.4. 稳定性改进
本版本中值得注意的稳定性改进。
作业回收改进 - 修复了在作业开始之前回收等待中的作业的根本原因,这种情况经常发生在控制节点和混合节点上的容量接近 100% 时。
基于 Operator 的部署稳定性改进 - 解决了许多控制 pod 部署错误地将彼此标记为脱机的问题。现在,水平扩展基于 Operator 的部署更加稳定。
13.1.5. 指标增强
本版本中添加的指标以跟踪。
awx_database_connections_total - 跟踪当前打开的数据库连接数。在监控中包含此指标可以帮助识别因缺少可用数据库连接而发生的错误。
callback_receiver_event_processing_avg_seconds - “回调接收器 worker 处理输出的落后程度”的代理。如果此数字一直很大,请考虑水平扩展控制平面并降低节点上的
capacity_adjustment值。
13.1.6. LDAP 登录和基本身份验证
对身份验证后端进行了增强,该后端将 LDAP 配置与 AWX 中的组织和团队同步。现在,使用 LDAP 组和组织以及团队之间的大量映射登录的速度比以前版本快 10 倍。
13.2. 容量规划
13.2.1. 容量规划示例练习
确定支持所需工作负载的实例数量和大小必须考虑以下因素。
托管主机
每台主机每小时的任务数
您想要支持的最大并发作业数
作业上设置的最大 fork 数
您首选的部署节点大小(CPU/内存/磁盘)
有了这些数据,您可以计算出每小时的任务数,即集群需要控制容量来处理的任务数;以及您需要能够运行峰值负载的“fork”数或容量,即集群需要执行容量来运行的任务数。
例如,要为具有以下配置的集群进行规划。
300 台托管主机
每台主机每小时 1,000 个任务,或每台主机每分钟 16 个任务
10 个并发作业
在剧本上设置了 5 个 fork
平均事件大小为 1 MB
首选的节点大小为 4 个 CPU 和 16 GB 内存,磁盘评级为 3000 IOPs
已知因素
要运行 10 个并发作业,您至少需要 (10 个作业 * 5 个 fork) + (10 个作业 * 作业的 1 个基本任务影响) = 60 个执行容量
要控制 10 个并发作业,您至少需要 10 个控制容量。
运行 1000 个任务 * 300 台托管主机/小时将产生至少 300,000 个事件/小时。您需要运行该作业才能准确了解它产生了多少事件,因为这取决于具体的任务和详细程度。例如,在一台主机上,详细程度为 1 的打印“Hello World”的调试任务会产生 6 个作业事件。详细程度为 3 时,它在一台主机上会产生 34 个作业事件。因此,估计该任务至少会产生 6 个事件。这意味着,更接近于 3,000,000 个事件/小时,或大约 833 个事件/秒。
要确定需要多少个执行节点和控制节点,请参考以下表格中的实验结果,该表格显示了单个控制节点与 5 个相同大小的执行节点(API 容量列)的观察到的事件处理速率。作业模板的默认“forks”设置为 5,因此使用此默认设置,控制节点可以分派给执行节点的作业的最大数量将使 5 个具有相同 CPU/RAM 使用率的执行节点达到其容量的 100%,从而达到之前提到的 1:5 的控制与执行容量比率。
节点 |
API 容量 |
默认执行容量 |
默认控制容量 |
容量使用率为 100% 时的平均事件处理速率 |
容量使用率为 50% 时的平均事件处理速率 |
容量使用率为 40% 时的平均事件处理速率 |
|---|---|---|---|---|---|---|
4 核 CPU @ 2.5Ghz,16 GB RAM 控制节点,最大 3000 IOPs 磁盘 |
100 - 300 个请求/秒 |
n/a |
137 个作业 |
1100 个/秒 |
1400 个/秒 |
1630 个/秒 |
4 核 CPU @ 2.5Ghz,16 GB RAM 执行节点,最大 3000 IOPs 磁盘 |
n/a |
137 |
0 |
n/a |
n/a |
n/a |
4 核 CPU @ 2.5Ghz,16 GB RAM 数据库节点,最大 3000 IOPs 磁盘 |
n/a |
n/a |
n/a |
n/a |
n/a |
n/a |
此表表明,控制作业与控制节点上的作业事件处理存在竞争。因此,过度配置控制容量会对减少处理时间产生积极影响。当处理时间较长时,用户可能会在作业运行和他们在 API 或 UI 中查看输出之间遇到延迟。
对于在 300 个托管主机上执行的示例工作负载,每个主机执行 1000 个任务/小时,10 个并发作业,在剧本中设置 forks 为 5,平均事件大小为 1 Mb,请执行以下操作
部署 1 个执行节点、1 个控制节点、1 个 4 核 CPU @ 2.5Ghz、16 GB RAM 数据库节点,磁盘具有约 3000 IOPs
保留作业模板的默认 forks 设置为 5
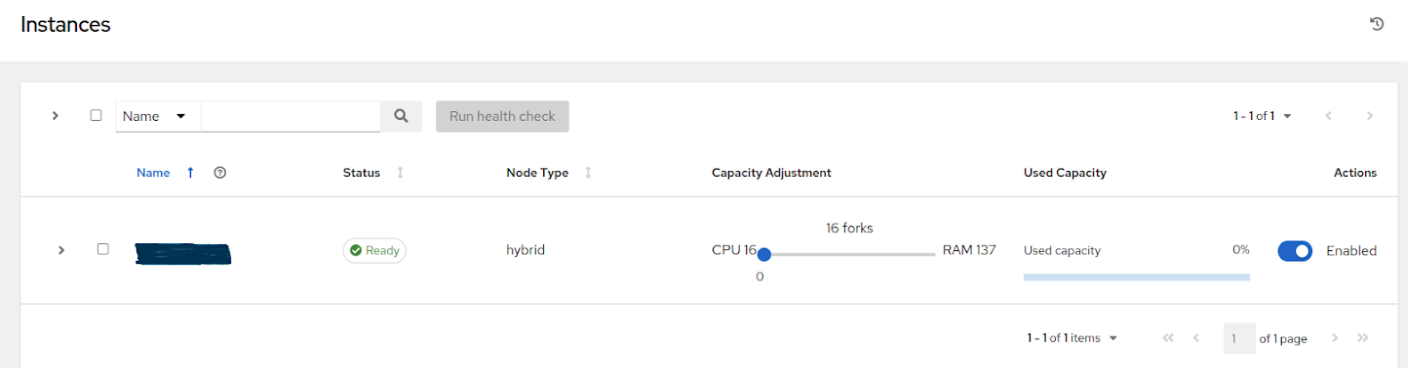
使用控制节点上的容量调整功能将容量降低到 16(最低值),以便为处理事件保留更多控制节点的容量
13.2.2. 影响节点大小选择因素
之前的练习是在集群管理员已经拥有首选节点大小的情况下完成的,该节点大小恰好是 AWX 的最小推荐节点大小。增加节点上的 RAM 和 CPU 会增加实例的计算容量。对于每种实例类型,都有不同的考虑因素,解释了为什么要垂直扩展节点。
13.2.2.1. 控制节点
垂直扩展控制节点会增加它可以执行控制任务的作业数量,这需要更多 CPU 和内存。通常,建议按相同比例扩展 CPU 和内存(例如 1 个 CPU:4 GB RAM)。即使在观察到内存使用量很高的情况下,增加实例的 CPU 也可以缓解压力,因为控制节点的大多数内存使用量通常来自未处理的事件。
如性能改进部分所述,增加 CPU 数量也可以提高控制节点的作业事件处理速率。目前,垂直扩展控制节点不会增加处理 Web 请求的工作人员数量,因此,如果要提高 API 可用性,则水平扩展更有效。
13.2.2.2. 执行节点
垂直扩展执行节点将为作业执行提供更多 forks。如示例中所述,具有 16 GB 内存的主机默认情况下将被分配运行 137 个“forks”的容量,在默认设置(每个作业 5 个 forks)下,它将能够同时运行大约 22 个作业。通常,建议按相同比例扩展 CPU 和内存。与控制节点和混合节点类似,每个执行实例都有一个“容量调整”,可用于将实际利用率与 AWX 做出的容量使用量估计相一致。默认情况下,所有节点都设置为 AWX 估计节点拥有的容量范围的最高端。如果实际监控数据显示节点被过度利用,则降低容量调整可以帮助将实际使用量与估计值相一致。
垂直扩展执行将完全按照用户的预期,增加实例可以运行的并发作业数量。一个缺点是,在同一执行节点上并发运行的作业,虽然在无法访问彼此数据(例如无法访问彼此数据)的意义上彼此隔离,但如果某个特定作业非常消耗资源,并且压倒节点,使其性能下降到影响整个节点的程度,则可能会影响其他作业的性能。水平扩展执行层(例如部署更多执行节点)可以提供一些工作负载的额外隔离,还可以允许管理员将不同的实例分配给不同的实例组,然后可以将这些实例组分配给组织、库存或作业模板。这可以实现类似于只能用于针对“生产”库存运行作业的实例组的功能,这样,开发作业就不会占用容量并导致优先级更高的作业排队等待容量。
13.2.2.3. 跳跃节点
跳跃节点的内存和 CPU 利用率非常低,垂直扩展跳跃节点没有显著的动机。将作为许多执行节点与控制平面之间唯一连接的跳跃节点应监测其网络带宽利用率,如果发现其网络带宽饱和,则可能需要考虑对网络进行更改。
13.2.2.4. 混合节点
混合节点同时执行执行和控制任务,因此垂直扩展这些节点既会增加它们可以运行的作业数量,现在在 4.3.0 版本中,还会增加它们可以处理的事件数量。
13.2.3. 基于 Operator 的部署的容量规划
对于基于 Operator 的部署,请参考Ansible AWX Operator 文档。
13.3. 监控 AWX
最佳做法是在系统级别和应用程序级别监控 AWX 主机。系统级别监控将包括有关磁盘 I/O、RAM 利用率、CPU 利用率和网络流量的信息。
对于应用程序级别监控,AWX 在 API 端点 /api/v2/metrics 上提供 Prometheus 风格的指标。这可用于监控有关作业状态的聚合数据以及子系统性能,例如作业输出处理或作业调度。
监控主机的实际 CPU 和内存利用率非常重要,因为实例的容量管理不会动态地内省主机的实际资源使用情况。自动化的资源影响将根据剧本的实际执行情况而有所不同。例如,许多云或网络模块在运行 Ansible 剧本的节点(执行节点)上执行大部分实际处理,这可能对 AWX 产生与在许多主机上运行 yum update 时的影响截然不同,在此期间,执行节点的大部分时间都用于等待结果。
如果 CPU 或内存使用率很高,请考虑降低 AWX 中受影响实例的容量调整。这将限制在此实例上运行或由该实例控制的作业数量。
将此与应用程序级别指标结合使用可以帮助识别应用程序在何时出现服务下降时发生的事件,以及是否发生了任何服务下降。拥有有关 AWX 性能随时间推移的信息对于诊断问题或进行未来增长的容量规划非常有用。
13.4. 数据库设置
以下是在数据库中可配置的设置,这些设置可能有助于提高性能
自动清理。将此 PostgreSQL 设置设为 true 是一个良好的做法。但是,如果数据库从未处于空闲状态,则不会进行自动清理。如果观察到自动清理不足以清理数据库磁盘上的空间,那么在特定维护窗口内计划特定的清理任务可以作为解决方案。
GUC 参数。以下是一些建议用于 PostgreSQL 中内存管理的 GUC(Grand Unified Configuration)参数,这有助于提高数据库服务器的性能。还提供了每个参数的推荐设置。
shared_buffers(整数)work_mem(整数)maintenance_work_mem(整数)
所有这些参数都位于 postgresql.conf 文件(位于 $PDATA 目录中)下,该文件管理数据库服务器的配置。
shared_buffers 参数确定为服务器分配多少内存用于缓存数据。在 postgresql.conf 中设置,此参数的默认值为
#sharedPostgres_buffers = 128MB
该值应设置为机器总 RAM 的 15%-25%。例如:如果机器的 RAM 大小为 32 GB,那么 shared_buffers 的推荐值为 8 GB。请注意,更改此设置后需要重新启动数据库服务器。
work_mem 参数基本上提供了在写入临时磁盘文件之前由内部排序操作和哈希表使用的内存量。排序操作用于排序、distinct 和合并连接操作。哈希表用于哈希连接和基于哈希的聚合。在 postgresql.conf 中设置,此参数的默认值为
#work_mem = 4MB
设置 work_mem 参数的正确值可以减少磁盘交换,从而使查询速度更快。
我们可以使用以下公式计算数据库服务器的最佳 work_mem 值
Total RAM * 0.25 / max_connections
max_connections 参数是用于指定与数据库服务器的并发连接最大数量的 GUC 参数之一。请注意,如果与数据库的打开连接太多,则设置较大的 work_mem 会导致问题,例如 PostgreSQL 服务器内存不足 (OOM)。
maintenance_work_mem 参数基本上提供了由维护操作(例如清理、创建索引和修改表添加外键操作)使用的最大内存量。在 postgresql.conf 中设置,此参数的默认值为
#maintenance_work_mem = 64MB
建议将此值设置为高于 work_mem;这可以提高清理性能。通常,应将其计算为
Total RAM * 0.05
13.4.1. 最大连接数
对于确定 max_connections 值的实际方法,这里概述了适用于 AWX 的一个概略公式。数据库连接将随着控制节点和混合节点的数量而扩展。每个节点的连接需求列在下面。
回调接收器工作器:每个节点 4 个连接或每个节点的 CPU 数量,取较大值
调度器工作进程:实例(分叉)容量加 7
uWSGI 工作进程:每个节点 16 个连接
监听器和辅助服务:每个节点 4 个连接
为安装程序和其他操作保留:总共 5 个连接
这些点中的每一个都代表高负载情况下预期的最大连接使用情况。要应用此方法,请考虑一个包含 3 个混合节点的集群,每个节点具有 8 个 CPU 和 16 GB 的内存。容量公式将根据内存和容量公式确定每个节点 132 个分叉的容量。
(3 个节点) x ( (8 个 CPU/节点) x (1 个连接/CPU) + (132 个分叉/节点) x (1 个连接/分叉) + (7 个连接/节点) + (16 个连接/节点) + (4 个连接/节点) ) + (5 个连接)
将所有组件加起来,此示例集群的总值为 506。实际上,这意味着 max_connections 应该设置为高于此值。应添加额外的连接以考虑其他平台组件。
此计算对每个节点的分叉数量最为敏感。数据库连接在作业开始和结束时短暂打开。在许多作业同时启动的突发情况下,最有可能达到理论上的最大打开数据库连接数。可以通过修改实例的有效容量来调整并发启动的作业数。这可以通过 SYSTEM_TASK_ABS_MEM 设置、实例上的容量调整,或通过实例组的最大作业数或最大分叉数来完成。
13.4.2. AWX 设置
许多 AWX 设置可以通过 AWX UI 或 API 进行设置。还有一些其他设置只能作为基于文件的设置提供。有关这些设置的具体设置位置,请参阅产品文档。本节将重点介绍管理员可能希望调整这些值的原因。
13.4.2.1. AWX UI 中的实时事件
事件广播到所有节点,以便可以将事件通过 websocket 传输到连接到控制节点 Web 服务的任何客户端。这项任务很昂贵,并且随着集群产生的事件数量和控制节点数量的增加而变得更加昂贵,因为所有事件都会广播到所有节点,而不管有多少客户端订阅了特定作业。
有一些设置允许您影响作业事件在 UI 中的显示方式和通过 websocket 的传输方式。
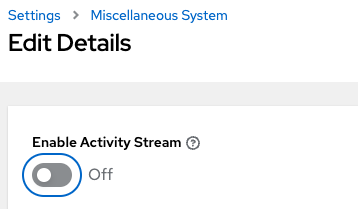
对于具有大量作业事件负载的大型集群,避免额外开销的一种简单方法是禁用实时流式传输事件(事件仅在对作业输出详细信息页面进行硬刷新时加载)。可以通过将 UI_LIVE_UPDATES_ENABLED 设置为 False 或从 AWX UI 杂项系统设置窗口将 **启用活动流** 切换到 **关闭** 来实现。
如果无法禁用实时流式传输事件,对于具有大量事件的非常详细的作业,管理员可以考虑减少每秒显示的事件数量,或者在 UI 中截断或隐藏事件。以下设置都解决了事件速率或大小问题。
# Returned in the header on event api lists as a recommendation to the UI
# on how many events to display before truncating/hiding
MAX_UI_JOB_EVENTS = 4000
# The maximum size of the ansible callback event's "res" data structure,
# (the "res" is the full "result" of the module)
# beyond this limit and the value will be removed (e.g. truncated)
MAX_EVENT_RES_DATA = 700000
# Note: These settings may be overridden by database settings.
EVENT_STDOUT_MAX_BYTES_DISPLAY = 1024
MAX_WEBSOCKET_EVENT_RATE = 30
# The amount of time before a stdout file is expired and removed locally
# Note that this can be recreated if the stdout is downloaded
LOCAL_STDOUT_EXPIRE_TIME = 2592000
13.4.2.2. 作业事件处理(回调接收器)设置
回调接收器是一个具有多个工作进程的进程。生成的工作进程数量由设置 JOB_EVENT_WORKERS 确定。这些工作进程从 Redis 中的队列中提取事件,作业的相应调度器工作进程会将未处理的事件放入队列中,以便结果可用。如 性能改进 部分所述,此工作进程数量会根据控制实例上检测到的 CPU 数量而增加。以前,此设置硬编码为 4 个工作进程,管理员必须通过每个控制节点上的自定义设置文件来设置此基于文件的设置。
管理员仍然可以修改此设置,但要注意,不建议将值设置为每个 CPU 1 个工作进程以上或少于 4 个工作进程。更大的值将有更多工作进程可用以清除 Redis 队列,因为事件流式传输到 AWX,但可能会与其他进程争夺 CPU 秒。较低的工作进程值可能会与在节点上也已显着增加了其 UWSGI 工作进程数量的节点争夺较少的 CPU,以优先处理 Web 请求的提供。
13.4.2.3. 任务管理器(作业调度)设置
任务管理器是一个定期任务,它会收集需要调度的任务,并确定哪些实例具有容量并有资格运行它们。它的工作是查找和分配控制和执行实例,将作业的状态更新为等待状态,并通过 pg_notify 将消息发送到控制节点,以便调度器获取任务并开始运行它。
如 性能改进 部分所述,在 4.3 版本中对该过程进行了一些优化和重构。其中一项重构是修复了一个缺陷,当任务管理器达到其超时时间时,它会以一种无法完成任何进度的状态终止。实施了多项更改来修复此问题,因此,当任务管理器接近其超时时间时,它会努力退出并提交在该运行期间完成的任何进度。这些问题通常出现在有数千个待处理作业时,因此可能不适用于您的用例。
限制任务管理器在一个运行中尝试完成多少工作的第一个“短路”是 START_TASK_LIMIT。默认值为 100 个作业,这是一个安全的默认值。如果有剩余的作业需要调度,则会在当前运行结束后立即安排任务管理器的新的运行。如果用户愿意冒着潜在的更长时间的单个任务管理器运行的风险,以便在单个运行中启动更多作业,可以考虑增加 START_TASK_LIMIT。一项指标(Prometheus 指标)在 /api/v2/metrics 中可用,用于观察任务管理器的单个运行持续时间是“task_manager__schedule_seconds”。
作为对过长时间运行的任务管理器的安全措施,存在一个超时,由设置“TASK_MANAGER_TIMEOUT”确定。此时,任务管理器将开始退出任何循环并尝试提交其完成的任何进度。该任务实际上不会被杀死,直到 TASK_MANAGER_TIMEOUT + TASK_MANAGER_TIMEOUT_GRACE_PERIOD 秒过去。
13.5. 其他资源
对于具有高水平的 API 交互的工作负载,最佳做法包括
使用负载均衡器
限制速率
将每个节点的最大连接数设置为 100
使用动态清单源,而不是通过 API 单独创建清单主机
使用 webhook 通知,而不是轮询作业状态
自发布博客以来,在领域中对身份验证方法进行了额外的观察。对于将在短时间内连续发出大量请求的自动化客户端,使用令牌是一种最佳做法,因为根据用户类型,使用基本身份验证可能会产生额外的开销。例如,使用基本身份验证的 LDAP 用户会触发一个进程来协调是否正确将 LDAP 用户映射到特定的组织、团队和角色。有关如何生成和使用令牌的详细信息,请参阅 基于令牌的身份验证。